

【摘 要】一篇英文新闻稿件的生产传播流程中,稿件修改是一个重要环节。在媒体深度融合发展进程不断推进的今天,利用人工智能、大数据技术辅助完成部分润稿工作,减少其中的经验性重复的部分,可进一步解放采编人员的生产力。本文从媒体智能化升级探索中,英文智能校对、措辞润色及稿件评估等技术在英文智能辅助润稿场景的背景及实践切入,对新华社“英文智能润稿助手”的相关工作进行了阐述与展望。
【关键词】智能校对;措辞润色;稿件评估;新闻生产;人工智能
导语
随着媒体深度融合发展的进程不断推进,智能化技术在新闻“采编发供”全流程生产过程中,扮演着越来越重要的角色。近年来,智能采写、自动写稿、新闻推荐与聚合分发等人工智能应用层出不穷,如何利用智能算法更加深度地赋能稿件生产,仍然是新闻技术工作者一直探索的方向。
众所周知,一篇合格的英文稿件一般在经记者采写后,还需初审、加工整理、校对等编辑修改流程,才可进入签发、供稿等环节。其中,编辑修改流程是任何一个从事新闻工作人员的基本功,一篇新闻稿件往往经过这一步,可实现从“半成品”到“成品”的蜕变,进一步提升稿件质量。这部分工作压力大,同时技术含量较高, 如果智能算法可以辅助完成部分编辑修改工作,减少其中的经验性重复的部分,使得记者有更多的时间、精力投入调查研究和独家、深度稿件的采写。
我们围绕英文稿件检查校对、措辞优化与评分评语等方面对“英文智能润稿”场景进行了技术调研与算法工程化实践,打造了可从多方面辅助编辑工作的“英文智能润稿助手”。本文将对其研发背景、实现思路与未来展望进行阐述。
1.英文智能润稿的机遇与挑战
1.1 英文智能校对
英文校对工作对保证英文出版物的质量起着重要的作用。英文出版物中的常见错误包括单词、语法、知识性、逻辑性等方面,需要校对人员具备扎实的英语基础,广泛的知识面和良好的心理素质才能判断出来并予以纠正。[1] 为了保证英文稿件的准确无误,尽管编辑人员为此付出了巨大的努力,但有时受各方面主客观条件约束,仍可能出现单词或语法错误,造成稿件传播的不良影响。
谈及英文自动校对技术,多数人会想到Word 自带的“拼写检查”功能。与检查单词拼写相比,英文语法检查要复杂得多,它需要考察句子中的逻辑关系,包括主谓搭配、介词使用、时态表达等多达 28 种(国际 CONLL-2014 评测任务中将错误类型共分为 28 种)的“全错误类型”。[2] 该技术应用广泛,除了新闻行业外,还在英语作文、电子邮件、PPT 文稿及翻译文件等方面均有大量使用场景。相关商业化产品在市面上也多种多样,从微软Office、金山WPS 类企业办公软件,到 Grammarly、Typely、Ginger 等英语写作校对工具,其检校效果、产品体验各有特色。
1.2 英文措辞润色
英文措辞表达往往影响着文章的质量。对于英文采编人员而言,面对新闻创作时要表达同样或相似意思的情况,如果能够做到用词准确、优美与多变,无疑可以进一步改善文章的第一印象。另一方面,当采编人员长时间沉浸在日常稿件编辑修改工作中,有时会造成思维惯性,稿件词库与写作风格固定,遇到词语匮乏的问题, 导致文章平淡无味。
措辞智能润色技术方面,传统的基于单词词性与句子语法规则的润色技术往往受限于知识库的规模,最终会面临效果提升的瓶颈。随着人工智能算力与算法的迭代发展,Google 公司推出 3 亿参数的 BERT、OpenAI 公司推出的 1750 亿参数的 GPT-3 等语言预训练模型,在自动翻译、智能问答、机器阅读理解等场景都有着惊艳的效果。他山之石可以攻玉,相关模型可以迁移应用于措辞智能润色功能中。模型经过大量文本的“学习”,当发现有更高概率的词汇或短语匹配当前的语境时,就会预测出更合适的替换建议,使文章在精准、形象的基础上画龙点睛,增强文章的表现力。
1.3 英文稿件评估
英文稿件的编辑过程中,一套合理的稿件评估体系尤为重要。不仅可以将文章的各维度指标对号入座,在流程化、标准化下提升编辑审改效率;还可以使稿件的优缺点一目了然,作者更快地查缺补漏,对稿件进行针对性修改。
有了完善的评估体系,英文稿件自动评估算法就有了优化目标。早在 2014 年托福评分系统改革起,托福作文就从原来的纯人工阅卷变成 E-Rater 电脑阅卷与人工阅卷配合打分,然后综合两者的平均值。随着越来越多的机器评分软件走入大众视野,用户对于机器评分的准确合理性也逐渐认可。例如图 1 是我们在稿件评估方面做的一些探索性尝试,它实现了对推特稿件的选题立意、价值导向、语法文法等主题、语义信息的建模分析,对稿件进行签发热度预测。同样,通过深度学习模型可对稿件进行更多方面的评估打分,提示稿件潜在的优化空间,辅助采编人员对稿件进行精准化修改。
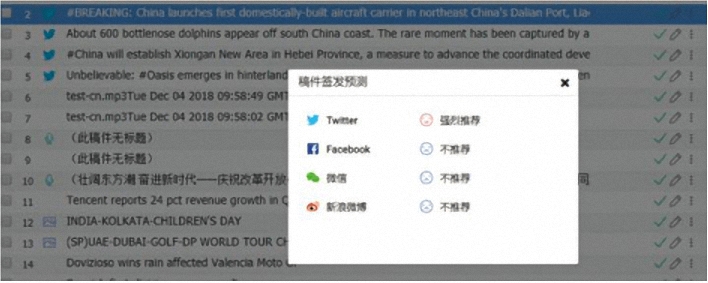
图1 稿件评估的初期探索——稿件签发预测
2. 英文智能润稿的探索与实践
2.1 采编发定制的英文智能检校
稿件智能化检校工作需要对稿件的标题、正文、关键词、摘要等文字内容进行机器自动核校,检查范围包括拼写错误、时态错误、搭配错误、常识性错误、用词缺失与冗余等方面,同时需要对各类错误给予修改提示, 辅助编辑提高稿件的准确度。
经过与商业化产品的对比分析,一套适合新闻生产领域的英文检校产品需解决如下几个问题。一是通讯社新闻报道有电头信息、报道用词等业务规范,在通用算法模型基础上要做好业务定制;二是实际检校过程中难免存在误识别、漏识别现象,要做好检校词库规范的持续反馈升级机制;三是稿件差错类型多样,产品设计时要兼容并包优秀算法互补,使检校效果达到最优。
为此,我们定制推出了适合新华社采编发稿规范的、多模型算法融合的检校算法。首先,算法实现了高亮错词并建议词提示,它不仅支持超过 300 万词汇的多词库高效检校,还对稿件易混淆词、常识性描述、电头时间地点信息进行准确核校,实现了围绕新闻采编业务的定制优化;其次,算法可通过机器学习挖掘新华社成品稿库中的高频新词,同时对检校修改操作进行大数据分析,定期对检校模型进行升级;最后, 算法集众家所长,目前不仅涵盖自主研发的外文拼写、语法检查技术, 还引入 LanguageTool、Fluency Boost Learning[3] 等开源项目与学术方面的最新算法成果。表1 为部分检校效果举例。
表1 “英文智能润稿助手”部分检校效果举例
| 错误类型 | 来源(下划线部分为错误表达) | 修改建议 |
| 稿件电头错误 | TAIWAN.Aug.6(Xnhua)-Zhoupu,a countv with a population of 142.800 in northwest China's Gansu Proviner--研发团队测试样例,电头省会地点与正文省名不匹配 | LANZHOU |
| 常识错误 | This pnxlurt was released on Thnrsdav.27 June 2017.--互联网测试样例.存在日期与星期几不匹配问题 | Tuesday,27 Junt 2017 |
| 冠词错误 | The founders of the projeet.such as Coundenhove-Kalergi and Jean Monnet.alwavs assumed there wouId be governmenet not bv eleeted statesmen but by teehnoerals.-New Stateman.2012/01/10 | a government |
| 介词错误 | In Wiseonsin,public-sector unions mobilised tens of thousands workers who took to the streets to protest against Republican plans to restriet colleetive bargaining rights-New Statesman,2012/01/11 | of workers |
| 代词错误 | "I think they're disturbed over nothing."he said of mine opponents.-the Washington Daily News.2012/01/10 | my |
| 形容词搭配错误 | Richard G.Steier.a marine conservation professor at the University of Alaska from 1930 to 2010,work on offshore oil issues.spill prevrntion, resvention,damage assessment and restoration,and consults globally on energy and environment issues.-Los Angeles Times, 2012/01/10 | environmental |
| 主谓一致错误 | And when the value of stocks and bonds go down,the value of retirement aeeounts that own stoeks and bonds falls,too.-USA Today. 2011/01/12 | goes |
| 形容词语序错误 | Why does eyeryonv pretend that Gary is some big nice metropolis?-Chicago Sun-Times.2012/01/11 | nice big |
| 常见易混淆名词 | "be it imported or horn-produeed.food sold in the domestic market should be strictly supervised aceonling to law."said Dang Qianying.an offical with the State Administration for Market Regulation.--新华社对外部提供测试样例 | offcial |
| 单复数搭配错误 | A reputation of danger and hardship proeeds the Sydney to Hobart--and with pIenty of good reason--新华社悉尼分社提供测试样例 | reasons |
2.2 多模型融合的措辞润色技术
英文措辞润色技术经过若干年发展,已从传统的基于英文词典、知识图谱类语料库(例如WordNet)的同义词替换,发展到了基于海量语料库机器学习的算法模型预测。前文提到,语言模型技术可实现根据上下文预测当前位置最合适的单词,实现稿件的措辞润色效果。
在经过不同模型效果对比实验后,我们引入了微软亚洲研究院提出的 UniLM 语言模型 [4] 作为稿件措辞润色的技术选型。它基于英文维基百科与 BookCorpus 开源数据库训练,是一个以多层 Transformer 网络为核心的深度学习算法模型,可差异化配置自注意遮罩机制,更好地对文本信息进行聚合分析与建模,较其他预训练模型(例如 BERT 等)更加适合大量替换预测的措辞润色场景。
表2 为“The wine he sent to me as my birthday gift is too strong to drink”句子中目标词“strong”在不同算法下的替换效果对比。经语言流畅度模型评估后,算法得出UniLM 的半遮盖策略效果的“powerful”效果最佳。
表2 “英文润稿助手”措辞润色效果举例
| 算法依据 | 替换建议 | 算法替换分析 | |
| 措辞同义性 | 上下文相关性 | ||
| WoradNet(语料库匹配) | hard、solid、stiff、firm | 高 | 低 |
| UniLM(不遮盖策略) | stronner、strongly、hard、much | 高 | 一般 |
| UniLM(完全遮盖策略) | hot、thick、sweet、much | 一般 | 高 |
| UniLM(半遮盖策略) | tough、powerful、potent、hard | 较高 | 较高 |
2.3 多维度结合的稿件评估技术
借鉴英文写作考纲及作文打分依据,我们整理归纳了稿件评估体系的若干维度(如图 2 所示),从数据统计与主观分析两方面入手,对稿件评估任务进行针对性建模。
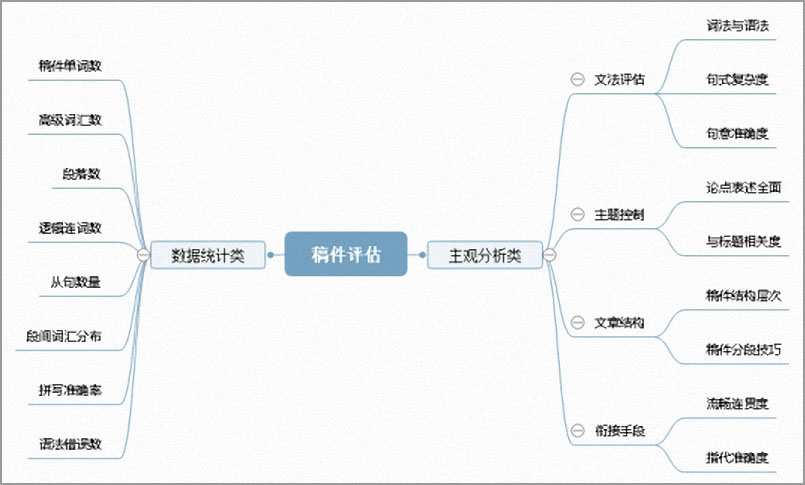
图2 稿件评估系统若干维度
技术层面,我们使用了兼具了稿件评估效果与训练数据自动扩充等问题的序数回归算法 [5] 作为多维度稿件评估技术架构选型。算法综合考虑稿件的高级词汇、逻辑连词及从句数量等数值特征,文法评估、主题控制、文章结构及衔接手段等主观特征等多个维度,进一步模拟采编流程审稿视角。例如图 3 的评估结果中显示,由于此篇稿件中语法错误较多,导致文章的“语法应用” 评星不高,进而直观提醒采编人员在后续创作中改进。
3. 英文智能润稿的下一步展望
智能辅助润稿助手已上线至新华社全媒体采编发系统,其英文稿件检校纠错、措辞润色和稿件评估等功能可以辅助英文稿件一键实现更优秀的表达。下一步,我们将继续结合采编场景,从如下几个方面展开探索研究。
3.1 句子与篇章粒度稿件修改
当前我们推出的“英文智能润稿工具”仍停留在单词或短语级别的修改,未来我们将在继续优化当前效果的基础上,对句子结构、段落设计等粗粒度稿件元素进行建模分析与润色建议,探索更智能的使用体验。
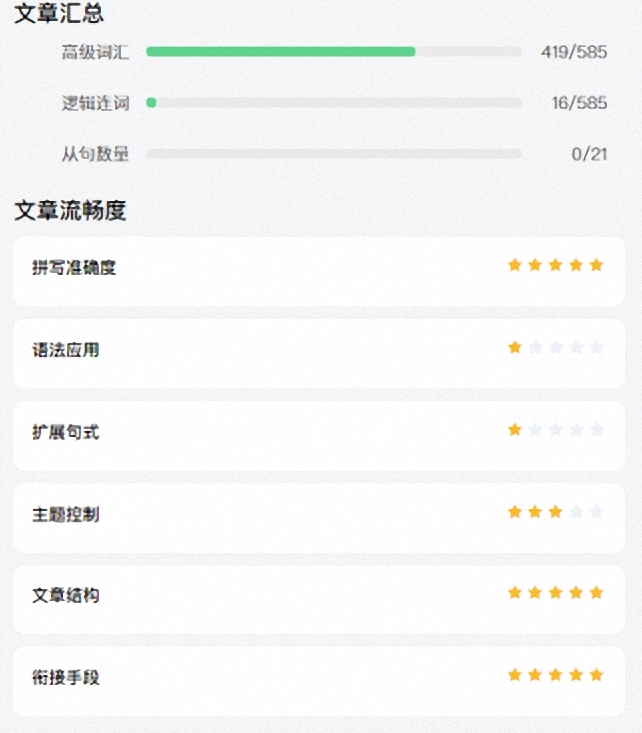
图3 英文智能润稿工具稿件评估使用截图
3.2 写作风格画像与写稿提示
在使用智能润稿功能时,采编人员每一次修改确认或忽略,都将对算法模型进行一次纠正经验反馈。在通用智能润稿模型的基础上,下一步我们也计划对用户行为数据进行个性化建模,探索个人写作风格画像与写稿补全提示等功能。
参考文献
[1]刘爱玲.浅谈英语校对工作[J].读与写(教育教学刊),2013(8):231.
[2]微软亚洲研究院.机器语法纠错能力新突破,微软小英变身英语写作老师[OL].https://www.msra.cn/zh-cn/news/features/engkoo-composition-score,2018-07-20.
[3]Ge T,Wei F,Zhou M.Fluency boost learning and inference for neural grammatical error correction[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics(Volume 1:Long Papers).2018:1055-1065.
[4]Bao H,Dong L,Wei F,et al.Unilmv2:Pseudo-masked language models for unified language model pre-training[J].arXiv preprint arXiv:2002.12804,2020.
[5]Chu W,Keerthi S S.New approaches to support vector ordinal regression[C]//Proceedings of the 22nd international conference on Machine learning.2005:145-152.
