

【摘 要】[目的] 探究稿件初检后学术不端检测比例超限(20%——40%)情况下最优的选稿方法。[方法] 将运用稿件中的主要关键词查询得到的文献、学术不端检测软件检测稿件得到的来源文献、第一作者和通信作者及其学术团队的历史文献中与稿件相似度较高的文献与稿件主要内容及文后参考文献进行比对,查证稿件的创新性及文献引用的合理性。[结果] 部分学术不端检测复制比超限稿件是由作者的写作不规范、引用不当、参考文献著录错误、学术不端检测软件的缺陷等造成的,经过规范化修改,仍然属于可选的好稿件。[结论] 对学术不端检测软件的文字复制比例为20%——40%,且复制内容不属于论文核心部分的稿件,只需要进行文献溯源分析、核心内容创新性分析、行文写作规范性分析,从中依然可筛选到一定比例的好论文。这部分论文可以退给作者适当修改后即可进入专家审稿流程。
【关键词】稿件;学术不端;学术不端检测系统;复制比;稿件筛选
我国作为世界第一科技论文大国,拥有庞大的主要由高校教师、在校研究生、研究院所研究人员、医院医生和少数企业科技人员等组成的学术论文作者群。在学术论文背后的年度考核、岗位聘用、职称评定、人才计划、评优奖励、课题立项等潜在利益的驱使下,少数作者会不自觉地陷入学术不端行为的泥淖。研究生的学术研究处于起步阶段,对学术不端行为的严重性认识不足,其也成为学术不端比例较高的群体。国内外近年来报道了很多由学术不端行为引发的撤稿事件,这应当引起期刊从业人员的高度重视。学术不端是全球性的问题,防范学术论文中的学术不端问题,需要编辑和全体科研工作者的共同努力[1]。
编辑作为学术论文第一道关口的“守门员”[2],责任重大。基于各种算法的学术不端检测软件的出现,在一定程度上为学术不端中原始抄袭内容的检测提供了便利。国内常用的学术不端检测软件主要有中国知网科技期刊学术不端文献检测系统、万方文献相似性检测服务系统、维普论文检测系统、PaperPass、大雅相似性分析系统[3]。但是,稿件中的深度学术不端(亦称为“隐性学术不端”)行为依然存在[4,5,6,7]。编辑由于长期对学术不端检测软件的高度依赖,容易形成错误的认识:有学术不端检测软件的把守,学术不端比例不超限(各编辑部规定的学术不端的文字复制比上限各不相同)的稿件不再有学术不端行为,已没有必要再进一步深究经过检测稿件的深度学术不端行为;一旦稿件的学术不端检测文字复制比例超过编辑部规定的上限,没有从不同角度进行分析便即刻作退稿处理;文字复制比超限稿件中不再有好稿件,不值得花费精力进一步分析。如此做法是武断的,也存在不妥;况且,学术不端检测软件的功能具有局限性,并非万能的[8]。学术不端检测软件检测的文字复制比例在稿件正式刊发之前可能还会发生变化[9,10,11],发表时间与上网时间存在一定的时间差[12],需要进一步分析其中的缘由并加以厘清。
学术不端检测软件仅仅解决了部分原始的复制问题,并没有解决深度学术不端的问题。我国学术不端问题易发有多方面的原因[13],远非学术不端检测软件能彻底解决。经过学术不端检测软件检测后文字复制比例超过部门规定上限的稿件,不能“一刀切”简单退稿了事,而要区别对待。本文主要针对学术不端检测软件文字复制比为20%——40%的稿件,其中也有部分稿件有很高的学术价值,只要满足所复制内容不是稿件的核心内容,就有必要对稿件进行复制内容的验证、深度学术不端检测和创新性分析。一旦稿件有创新性内容且处于学科热点领域,就可退给作者,让其对存在问题的内容进行修改,修改后即可进入下一个稿件处理流程,这才是正确的稿件取舍之道。
1 编辑对学术不端正反面的认识
1.1 学术不端的定义
2016年9月1日起施行的《高等学校预防与处理学术不端行为办法》将学术不端定义为:高等学校及其教学科研人员、管理人员和学生,在科学研究及相关活动中发生的违反公认的学术准则、违背学术诚信的行为。该定义虽然针对高校教师和学生,实际上对所有的科研人员均适用。该办法并对学术不端行为进行了严格的鉴定,可以简要归纳为:剽窃、抄袭、侵占他人学术成果;篡改他人研究成果;伪造科研数据、资料、文献、注释,或者捏造事实、编造虚假研究成果;不当署名;买卖论文、由他人代写或者为他人代写论文等行为。笔者认为作者自我复制和学术团队内成员之间互相复制,所刊发同系列论文之间的内容过度分割等行为依然属于学术不端范畴,但这些学术不端并未在该办法中出现,这是其不足。
2019年5月,国家新闻出版署发布《学术出版规范——期刊学术不端行为界定(CY/T 174—2019)》行业标准,从论文作者、期刊编辑人员、稿件审稿专家三个维度界定了可能出现的学术不端行为类型,扩展了学术不端的范围。这为判断和处理学术不端行为提供了可借鉴的行业依据。但遗憾的是,并未给出学术不端行为的定义、评判和处理学术不端的主体,以及鉴定学术不端的具体流程。
1.2 学术不端的测度
利益驱动下的学术不端行为是一个复杂的社会现象,很难以量化判定,这个量化的标准就是学术不端的测度。学术不端行为有很多类型,形成了一个学术不端行为集合,每种类型对应一个判定参数,即学术不端行为集合的一个判定元素。目前,第三方学术不端检测工具只能从复制、原始抄袭方面进行比对,其复制比就属于原始剽窃、抄袭的学术不端行为的判定参数。它虽然并不能代表所有的学术不端行为,但其中罗列的存在一定复制比的文献集合,加上稿件后参考文献列表,可使编辑较容易从提供的文献集合中找到可能存在的学术不端行为。
编辑判定稿件中是否存在学术不端行为,实际上就是根据已知的条件评判存在或可能存在的各种类型的学术不端。在大多数情况下,编辑只有借助第三方工具进行检测,或者借助文献数据库中同类文献的比对。在没有第三方检测工具或文献数据库的情况下,编辑很难发现稿件中存在的学术不端。编辑无法发现的学术不端,一般只有审稿专家从专业的角度进一步审视才能发现。
审稿专家从专业角度把控学术不端是最可靠的办法。但学科细化且发展迅速,形成了海量的文献数据,相关文献数量巨大,导致对审稿专家提出的要求更高。审稿专家在审稿过程中不仅要判断稿件的创新性,还要进行同类相关文献的查询和比对,工作量巨大。因此,要在审稿阶段就彻底判定稿件存在的学术不端十分困难。
目前,编辑将第三方检测工具作为学术不端检测的重要利器。很多编辑部都划定稿件的学术不端检测文字复制比例的上限作为判据,一旦超越上限,立即作退稿处理。在复制比等同于学术不端检测结果的背景下,稿件的复制比上限应该为多少?不同编辑部的意见并不一致。大多数编辑部将复制比上限设定在10%——20%的范围内。中国知网也并未给出系统检测的复制比上限,只是给出绿色、黄色、橙色和红色的颜色警示,声明复制比为稿件与检测文献中重合文字所占的比例大小。检测工具所显示的仅仅只是学术不端中复制内容的比例,而不是所有可能存在学术不端的总和。通过学术不端检测的稿件中可能还存在其他学术不端,而超过部门规定的文字复制比的稿件中依然也有好稿件,需要综合评定。笔者认为,不应将学术不端软件的测度固化,只有学术不端检测软件检测结果超过一定比例的稿件才需要重点筛查。一旦发现有创新性的稿件,可作退修处理,修改完善的稿件依然可以进入下一处理流程。但复制比较高的稿件,如超过了40%,说明来源于其他文献的文字过多,已经没有修改价值或者修改工作量较大,应坚决退稿。
1.3 学术不端检测文字复制比超限不完全等同于学术不端
根据学术不端的定义,学术不端是一切违背众所周知的学术诚信的不良行为,是各种学术不良行为的总称。用于稿件的学术不端检测软件,其命名从一开始就存在一定的误区,根据学术不端检测软件的算法,目前只能对最小复制单元作出检测,即目标检测稿件与比对文献之间存在完全相同的最小单元,才能被检测出来,一旦语序不同,所表达的意思相同或相似,则被视为与源文献无关,即目标稿件不存在复制行为。学术不端检测软件存在致命的缺陷,即无法对意思抄袭、改写、图片[14]、公式、语种互译、一稿多投、第三方代写代投[15,16]、内容调整后的表格等内容作出准确检测,这已经为行业人员所验证。通俗而言,目标比对对象中只有存在最小复制单元才能被学术不端软件检测出来,即有原始的复制、抄袭行为,才能被检测出来。学术不端检测软件在原始复制方面的检测确实是一个重要的利器,但并不能发现所有的学术不端行为。
另外,学术不端检测软件在不当引用方面也发挥着重要的作用。有些作者为了回避冲突文献,故意隐瞒与论文相关性较高的文献。一旦论文存在少量的复制内容,在学术不端检测软件的检测报告中会列出重合文字来源文献、对该文献标出引用与否、复制比等参数,比对后会发现稿件中的某些学术不端的蛛丝马迹,溯源寻踪后往往会发现稿件中存在更隐蔽的深层学术不端。
就学术不端检测软件发挥的作用而言,称其为“学术不端检测软件”有言过其实之嫌,更多的是复制内容的检测与发现、不当引用行为的提醒。因此,编辑人员误认为经过学术不端检测软件的稿件不再有学术不端行为是一种错误的认识。诚如孙雄勇等[17]所言,随着当前学术不端检测系统的使用,学术不端检测存在诸多难点。
1.4 软件缺陷导致复制比可能含有水分
学术不端检测软件目前难以做到十全十美,由于自身存在的缺陷以及“反抄袭检测”“论文撰写策略”等规避检测技术手段的出现,稿件中原始的抄袭、复制已经演变为隐式的深层次学术不端行为,学术不端检测软件对此也无能为力,检测软件显示的复制比仅仅是一种供编辑评判稿件是否存在过度复制的指标,并不能代表学术不端的全部。学术不端检测软件的固有缺陷导致其复制比显示的结果仅仅是一个粗略的参考依据,而并非绝对准确评判稿件学术不端的唯一参数。
不当引用、错误引用、文献错误和过度引用一般会增大复制比例,导致学术不端检测软件显示的比例失真。少数稿件因为存在不当引用和过度引用行为,出现学术不端检测比例超标,具体情形如下:(1)没有引用本该引用的文献;(2)引用格式错误;(3)过度引用文献内容(实际上是复制内容超过了检测软件规定的引用内容上限);(4)引用文献与检测软件认定的文献存在差异;(5)文献著录错误。
在大多数情况下,稿件的不当引用和过度引用的情况会导致文字复制比例超标,但经过简单处理即可解决。若只依据学术不端检测软件文字复制比例评判稿件学术质量,可能会导致部分好稿件流失。
2 对学术不端检测文字复制比例超限稿件的分析
2.1 编辑部关于学术不端检测文字复制比的选稿规定与做法
很多编辑部对防范稿件中的学术不端行为极其重视,做了很多具体的防范工作,特别是对学术不端检测结果比例方面作了硬性规定,不允许突破所规定的上限。部分期刊编辑部甚至通过主页、采编系统、《征稿启事》等方式公告,将来稿学术不端检测结果的最高比例限制在20%,甚至10%以下。一旦来稿的学术不端检测结果突破规定的上限,就实行“一刀切”,不作任何分析,强行退稿。
长期以来,编辑形成硬性的“一刀切”选稿模式,在稿件的初审过程中,编辑有权对学术不端显示比例超限的稿件实行即刻退稿。偶有少量稿件被要求改写检测软件发现的复制文字(红色文字部分),直到检测软件显示的复制比例低于部门规定的上限,才允许稿件进入下一个处理流程。实际上,这些做法并没有从根本上消除学术不端行为,只是变换了一种形式,通过文字改写隐藏了学术不端,来稿件中可能依然存在深度学术不端行为。
2.2 对不同文字复制比稿件的分析
笔者对《昆明理工大学学报(自然科学版)》和《昆明理工大学学报(社会科学版)》使用采编系统后的全部稿件关于学术不端的统计数据(来自中国知网学术不端文献检测系统)进行分析,发现:未检测出相似的来稿(复制比为0)的比例为7.8%/3.3%(自科版/社科版,下同),轻度相似来稿(0<复制比≤40%)的比例为86.9%/92.2%,中度相似来稿(40%<复制比≤50%)的比例为1.7%/2.3%,重度相似来稿(复制比>50%)的比例为3.6%/2.2%。从统计数据可见:复制比为0的稿件数量较少;轻度相似稿件的比例最大;而中度和重度相似稿件相对较少。编辑部通常对复制比为20%——40%的稿件关注度较低,多数作为“带病”稿件直接退稿了事。这样处理实际较为轻率,其中也有不错的稿子,只是需要进一步修改和加工而已。
学术不端检测软件显示的复制比能够帮助编辑发现作者的复制行为及其严重程度,其重要意义不言而喻。但是,由于学术不端检测软件的技术限制,其显示的复制比仅仅是一个参考值,而不是一个绝对值。因为学术不端检测软件在检测的过程中,作者的写作不规范等行为也会导致复制比增大,如引用不当、引用错误、参考文献有误等,这部分不当行为的文字字数也会作为学术不端计入文字复制比例中。如果编辑简单依据文字复制比超限实行退稿,可能会导致部分好稿件流失。因此,编辑需要对复制比有一个正确的认识。
编辑不能将学术不端完全等同于检测软件的复制比。复制比只是学术不端中的一个或几个类型,并不是对所有学术不端行为的检测;经过学术不端检测软件检测后的论文依然可能存在学术不端行为,且这种学术不端行为经过改头换面隐藏在稿件之中;随着比对文献源的变化,复制比在论文出版前还可能发生变化,不一定是一个定值;即使经过学术不端检测软件的检测,复制比较低的稿件中依然可能包含严重的学术不端行为,如观点抄袭、关键实验数据抄袭等。从表面来看复制比不高,但是这是对源文献的严重侵犯。因此,对学术不端行为及检测软件显示比例及其作用需要客观对待。
学术不端检测软件的检测不能完全取代人工判断学术不端的过程。人工判断稿件中的学术不端行为不可省略,主要依据就是对论文文献数据库中的同类文献、学术不端检测软件指向的重合文字来源文献源集合、稿件文后的参考文献集合,三者构成了评判稿件中的学术不端的重要文献佐证,可以溯源追踪和稿件比对,通过这个文献集合可以大体判断出稿件是否存在学术不端行为及稿件的创新性所在,一举几得。
3 编辑处理学术不端检测文字复制比超限稿件的最佳流程
编辑不一定对所有稿件涉及的学科方向都熟悉,往往只能通过稿件的同类文献来判断来稿的学术不端和创新性。同类文献就是编辑判断稿件学术质量的重要依据,同类文献数据库一般都比较庞大,不可能把稿件与全部文献进行比对。主要通过关键词、作者及其学术团队这几个重要参数查询得到的整个文献集合、学术不端检测软件指向的重合文字来源文献集合和稿件文后参考文献集合,将这三者合并得到参考文献总集合。通过一个相对合理的稿件处理流程(图1),最大程度地剔除学术不端稿件,保证所选稿件具有一定的创新性。
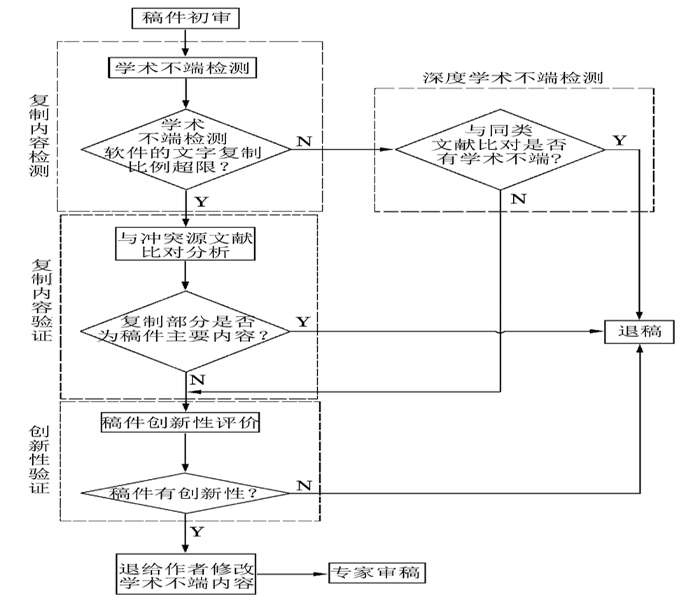
图1 学术不端检测比例超限稿件的处理流程
3.1 文字复制比检测
文字复制比检测是编辑初审稿件流程的第一步。该步骤就是通常所说的通过学术不端检测软件对来稿的学术不端进行检测,通过检测可以帮助编辑快速发现复制内容,并获得稿件复制情况的报告。通过该报告编辑可以知道复制内容占稿件的比例、学术不端的类型、冲突文献列表(重合文字来源文献)、冲突文献引用与否以及重合内容在稿件和文献中的比例及分布情况。
稿件总复制比是大多数编辑评判稿件能否进入下一个处理流程的重要指标:当稿件复制比小于部门规定的上限时,编辑往往会凭经验大致浏览一下稿件内容,简单判断一下稿件的创新性和所属学科方向,若无其他问题,即刻将稿件送给选定的审稿专家进行评审;若总复制比超过了部门规定的上限,即可实施退稿。如此做法,将会带来两个问题:(1)对于复制比不超标但隐含深度学术不端的稿件,其学术不端的发现工作自然转移到审稿专家的身上。多数审稿专家对稿件的评审主要是对稿件的创新性进行评判,取决于审稿专家的研究领域、学术能力、学术责任心等。当审稿专家不能准确评判稿件的学术创新性,同时未发现深度学术不端行为,并且稿件被编辑部录用时,隐性的学术不端将延续到出版后的论文中。所以,期刊编辑要在初审稿件时尽可能地发现学术不端,并在前期尽量剔除。(2)稿件的复制比虽然超过部门规定的上限,但低于40%,一旦简单退稿,会导致部分好稿件流失。这类稿件需要进一步分析复制比超标的原因,需要对复制内容进一步验证。
3.2 文字复制内容的验证
对稿件中复制内容的验证,这是编辑初审稿件流程的第二步。稿件有一定量的复制,并不意味着稿件彻底没有价值,需要对复制内容溯源。当稿件的复制比大于部门规定的上限,且大40%时,再进行学术不端分析耗时费力,已经没有实际意义,可以即刻退稿。但当复制比在20%——40%范围内,且超过了编辑部规定的学术不端检测结果上限时,就需要进一步验证复制内容的来源、分布及文献引用的合理性。要验证复制内容及其比例,重合文字来源文献就成为编辑追踪的首要目标。
(1) 复制内容来源的验证。验证复制内容的来源,就要分析重合文字来源文献。重合文字来源文献列表可提供稿件中复制内容的来源文献。编辑需要简单浏览重合文字来源文献,分析稿件与重合文字来源文献之间可能存在的逻辑关系。先从复制比较大的重合文字来源文献开始,分析来源文献是否包含在稿件正文后的参考文献列表中。如果文后参考文献列表中没有重合文字来源文献,说明作者可能有意隐瞒关键文献。在排除文献引用错误、文献著录错误后,就需要对重合文字比例较大的来源文献进行全文比对,甚至通过稿件的主要关键词查询得到的同类文献,与同类文献依次比对,确认稿件创新性内容是独立的,才可以进一步修改稿件。否则,就只有作退稿处理。如果稿件文后参考文献列表已经包含重合文字来源文献,特别是重合比例较高的文献,这时就需要进一步检查参考文献著录格式及文中引用关系是否正确。若著录及引用关系正确,则可能存在引用过度的情况,或者由于检测系统无法在文献数据库中追踪到作者列出的参考文献,此时需要作者调整引用内容。
(2) 复制内容分布的验证。稿件中的复制内容及其在全文中的分布位置十分重要。如果只是零星语句分布在不同位置,不是大比例抄袭,且复制内容已经引用,可能只是由于引用错误,或引用文献著录错误,或检测系统无法追踪到参考文献,导致复制比增大,这种情况是允许的,只要修改文献著录格式和引用关系,复制比一般都可以降低。相反,如果稿件中的复制内容过于集中,且处于稿件的核心位置,又不是自引或者学术团队之间的互引,也不存在文献著录错误或者引用关系错误,此类稿件即可退稿;如果稿件中的复制内容过于集中,但处于论文中非核心位置,此类稿件可以进一步修改复制内容后进入下一个处理流程。还有同类实验流程、计算方法等相同的稿件,作者为了减小工作量,直接从同类文献中复制,此时修改重复文字并不影响稿件的创新内容,因此这类稿件亦可进入下一个处理流程。综述类稿件复制比适当高一些,是正常现象。
(3) 复制内容引用合理性的验证。稿件中的复制内容与重合文字来源文献有同样的语句表达,编辑需要对重合文字进行合理性验证,即判断复制内容与重合文字来源文献之间是否存在合理的继承关系,一旦继承关系被打破,学术不端检测软件不认可这种继承关系,任何重合文字单元都被计入复制总和。验证复制内容引用的合理性,目的就是检查虽然有复制行为,但被复制文字在稿件中是相对合理的,只是作者写作不规范、参考文献著录错误和软件缺陷等导致复制比增大,并非作者刻意复制,这种情况下的稿件值得进一步验证。
首先,文献引用关系的合理性检查。与稿件冲突的主要文献在稿件中要有引用,并且按照引用格式正确标注,才能保证重合文字关联下的稿件和文献之间具有合理的继承关系。若稿件与重合文字来源文献之间缺少正确的引用关系,即丧失了继承关系,这会增大稿件的复制比,一旦复制内容涉及到稿件的核心内容,只有选择退稿。
其次,文献著录格式正确性检查。即使稿件正文中正确标注了文献的引用,但对应的文后参考文献著录错误,或者学术不端检测软件无法查询到引用文献,这种继承关系也会被打破,重合文字将被计入复制比,增大复制比。编辑检查文后参考文献著录的正确性,目的就是排除学术不端检测软件的缺陷导致稿件复制比增加的特殊情况。
再次,自引的合理性检查。自引是常见的引用行为,一般是同一作者对自己文献的引用或者同一学术团队成员之间的文献引用。主要检查稿件中作者自引和引用学术团队文献与稿件在学术方面的关联性及引用比例,防止同类论文之间的过度分割和过度引用,导致稿件创新性不足。同时,防止同类稿件部分内容交叉重复,此类内容具有复制的可能性,一旦此类内容复制过度,加上创新性不足,即可退稿。
最后,过度引用的检查。少量稿件中文献引用关系是合理的,文献著录格式也正确,但会出现文献引用过度问题,导致复制比过高。此类稿件主要看稿件类型和内容的创新性,论文有创新性,只要修改过度引用部分,即可进入下一个处理流程。
3.3 深度学术不端检测与创新性验证
可能含有很多种隐性学术不端行为的稿件,一般都经过了很严密的伪装和改头换面,甚至已经通过了学术不端检测工具的检测,复制比控制到很低的程度,符合编辑部学术不端检测规定的要求。这类稿件通常都能逃过编辑的初审,不会引起编辑的警觉。只有在高度负责和专业知识渊博的专家审稿过程中,以稿件内容创新性审查时才会以无创新性而实施退稿。但无论如何,创新性验证是识别学术不端的最好方法,无论学术不端以何种方式隐藏,其本质就是没有创新。
对学术不端稿件“一网打尽”的最好方法就是对稿件的创新性进行审查,既能够对深度学术不端进行审查,又能发现稿件是否具有创新性。当复制比处于20%——40%区间时,此类稿件都有重合文字来源文献,这类文献为期刊编辑提供了溯源与寻踪学术不端的最好路径,加上同类文献和稿件后的参考文献,找出文题和内容与稿件内容相似度较大的文献进行比对,就有了相对明确的比对目标。这类稿件最佳的处理流程如下:
(1) 通过稿件主要关键词,在文献数据库中查询到与稿件相似度较高的主要文献,并将该文献与稿件内容进行比对,查证两者主要内容的异同。稿件与同类文献存在学术不端且无创新则退稿;虽然存在一定复制比,但稿件主要内容有创新,则进入下一个处理流程。
(2) 将学术不端检测工具查询到的重合文字来源文献中相似度较高的文献与稿件内容进行比对,寻找稿件相比来源文献是否有创新性内容。有创新性内容,来源文献同时出现在稿件的参考文献列表中,但引用错误等导致复制比超限(≤40%),则进入下一个处理流程。稿件内容相比来源文献无创新,或者故意隐瞒相关性较高的来源文献,则退稿。
(3) 查询第一作者、通信作者及其学术团队相似度较高的历史文献,与稿件进行一一比对,对同一作者或同一学术团队论文之间的关联性进行检查,防止稿件过度拆分;或者由博硕士学位论文改写而成的论文。若稿件与第一作者、通信作者及其学术团队的历史文献相似度不高,且也并非由学位论文改写而来,则进入下一个处理流程,否则退稿。
4 结语及展望
期刊编辑需要准确理解学术不端的类型及其检测软件的局限性,特别是文字复制比及其意义。文字复制比符合部门规定上限的稿件并非都不存在学术不端行为,而文字复制比在20%——40%范围内的稿件也并非一无是处。期刊编辑不能仅凭学术不端检测软件的检测结果,就即刻作出取舍稿件的行为,而应该将软件检测结果和人工比对判断相结合,对同类文献、重合文字来源文献、作者及其学术团队的历史文献和稿件后参考文献与稿件进行比对,发现稿件的深度学术不端行为,寻找稿件的创新性内容。而对于复制比为20%——40%且具有较高创新性的稿件,经过修改完善,删除不当的文字复制后,仍然可以进入下一个审稿流程,直至最后被录用。随着学术不端检测软件功能的完善,正如中国知网旗下学术不端检测软件“常见问题解答”中所宣称的实现“语义”检测,那时学术不端行为将无处遁形。
参考文献
[1]周祝瑛,马冀.学术不端治理的国际经验探析[J].比较教育研究,2018,40(9):87-94.
[2]段桂花,张娅彭,于洋,等.当好科技期刊杜绝学术不端的“守门员”[J].编辑学报,2017,29(4):356-358.
[3]吴凌,李海霞,郭桃美.国内五个学术不端文献检测系统的对比研究[J].科技传播,2019,11(10):7-12.
[4]于海.隐性学术不端论文的鉴别方法[J].辽宁师专学报(自然科学版),2016,18(1):106-108.
[5]朱银周.期刊主体人员防范深度学术不端行为的职责分析[J].中国科技期刊研究,2014,25(11):1373-1378.
[6]张重毅,方梅.科技论文隐性学术不端行为判别特征分析[J].中国科技期刊研究,2019,30(1):24-28.
[7]郑泉.警惕深度学术不端共建学术道德规范[J].传播与版权,2019(9):158-160,163.
[8]郭卫兵,叶继元.学术失范、不端检测软件的功能、局限与对策——以学术研究规范为视角[J].图书馆论坛,2019,39(3):2-9.
[9]朱银周.稿件中学术不端行为检测结果的动态变化与成因分析[J].中国科技期刊研究,2018,29(2):130-136.
[10]肖骏,谢晓红,王淑华.论学术不端的深度防范[J].编辑学报,2017,29(4):365-367.
[11]徐婷婷,曹雅坤,曾礼娜,等.关于防范科技论文中“隐性”学术不端行为的建议[J].编辑学报,2018,30(1):58-60.
[12]张辉玲,白雪娜,崔建勋,等.学术不端文献的发表追溯及防范对策——基于185篇疑似学术不端文献的实证分析[J].中国科技期刊研究,2016,27(7):691-697.
[13]刘普.我国学术不端问题的现状与治理路径——基于媒体报道的64起学术不端典型案例的分析[J].中国科学基金,2018,32(6):637-644.
[14]叶青,林汉枫,张月红.图片中学术不端的类型与防范措施[J].编辑学报,2019,31(1):45-50.
[15]罗云梅,蒲素清,李缨来,等.华西期刊社1748篇疑似学术不端稿件的分析[J].编辑学报,2018,30(3):278-281.
[16]朱银周,唐虹.非法学术论文代理及其治理研究[J].昆明学院学报,2018,40(6):124-128.
[17]孙雄勇,耿崇,申艳.学术不端检测的难点及对策[J].中国科技期刊研究,2019,30(1):14-18.
