

【摘 要】文章在对现有人工智能监管规制梳理的基础上,集中探讨人工智能新闻出版监管难点与症结,进而提出优化路向与对策。针对人工智能归责难、受众隐私保护难、智能算法公正难等难点,提出完善人工智能新闻出版监管应延循探索主体归责办法、建立多维互促监管模式、为人工智能"祛魅"与降低智能新闻生产偏见等优化路向,并进一步探讨了建立人工智能新闻评测体系框架与指标。
【关键词】人工智能;新闻生产;监管难点;优化路向
建立在数据驱动的计算机深度学习与跨媒介协作基础上,智能系统写稿与分发行为已成为当下新闻出版领域的常态。未来人工智能技术必将继续洗礼新闻出版业的各个环节,进而形塑新型业态与关系。人工智能对接新闻出版之后孕育了广阔的创新空间,同时也带来了新的规制难点,需要仔细甄别并加以应对。
一、人工智能相关监管规制的兴起
应对人工智能浪潮并把握其给予经济社会的前景机遇,已成为世界多数国家的发展战略要义。在已有人工智能发展规划中,与鼓励扶持相伴的监管谋划初露端倪,体现了各国在人工智能领域的持续思考与科学态度。
近年来,美国、英国、日本等国家相继出台人工智能相关规划,对人工智能监管提出建设性思路与措施。2016年1月,日本制定第五期科学技术基本计划(2016-2020),提出建设“超智能社会”,将之描述为“社会需求被科学细分,人人得享优质服务,人工智能成为预测和提供相应服务的重要力量,虚拟空间和现实生活高度融合”的形态。该计划呼吁建立“更高级别的安全管理”,以应对所伴生的伦理法制问题。[1]同年10月,美国白宫指导有关机构制定并发布《为未来人工智能做好准备》(Preparing for the Future of Artificial Intelligence)与《美国国家人工智能研究与发展策略规划》(The National ArtiGcial Intelligence Research And Development Strategic Plan),后者提出对人工智能进行长期投资、开发有效的人类与人工智能协作方法、了解并解决人工智能的伦理法律和社会影响、确保人工智能系统的安全可靠、开发人工智能所需公共数据集和完善发展环境、制定人工智能技术测量和评估标准六大战略。121与之相似,英国高度重视人工智能领域的监管规制。在英国下议院2016年发布的《机器人技术和人工智能》(The Robotics and Artificial Intelligence)中,对人工智能已经和可能引发的道德伦理问题,提出通过“检验和确认”确保人工智能系统始终处于人类监管干预之下;主张重视解决人工智能带来的道德困境和社会问题。[3]同年,英国政府发布《人工智能:未来决策的机遇与影响》(Artificial Intelligence:Opportunities and Implications for the Future of Decision Making)研究报告,触及人工智能技术下的隐私保护以及智能算法的偏见问题。
上述背景下,相关行业组织与主张陆续涌现。2017年1月,Linkedln公司创始人之一瑞德•霍夫曼联合Omidyar网络基金创立人工智能伦理与治理基金;以埃隆•马斯克为代表的近千名人工智能领域企业家与专家联合签署发布阿西洛马人工智能23原则(Asilomar AI Principles),该宣言主要表达对人工智能研发应秉持的价值观的思考,提及人工智能伦理尺度和价值归属问题,主张智能开发使用“要与人类的价值观一致”。[4]2018年12月,欧盟发布《可信赖的人工智能道德准则草案》(Draft Ethics Guidelines for Trustworthy AI),强调人工智能应做到技术可靠并尊重人类基本权利与制度规则及价值观。
我国高度重视人工智能领域的发展与监管。2017年7月,国务院印发《新一代人工智能发展规划的通知》,从国家战略高度规划了当下至2030年我国人工智能发展的基本步骤。该通知提出制定促进人工智能发展的法律法规和伦理规范、完善支持人工智能发展的重点政策、建立人工智能技术标准和知识产权体系、建立人工智能安全监管和评估体系、大力加强人工智能劳动力培训、广泛开展人工智能科普活动六大措施。[5]三个月后,上海市发布《关于本市推动新一代人工智能发展的实施意见》,决定系统落实“智能上海(AI@SH)”行动,制定拓展人工智能融合场景与加强人工智能科研布局、营造人工智能多元创新生态等具体措施,目标是推动人工智能成为上海科技创新的新引擎。[6]2018年至2019年,由国家发展和改革委员会、工业和信息化部、上海市人民政府等主办的两届世界人工智能大会先后在上海召开,大会议题涵盖了对人工智能法治框架与路径的广泛探讨。
综合来看,目前各国对人工智能的监管引导尚处在探索尝试阶段,已有规制大多体现为导向性策略。究其原因,主要在于人工智能技术尚在发展演变之中,其对接各行业各领域之后催生的问题复杂多变,对其有效甄别并合理解决尚需时日。
二、人工智能新闻出版的监管难点
人工智能成为新闻出版重要动力的同时,也催生出新的问题和监管难点。人工智能新闻出版的互动性强、智能算法优势凸显,同时也带来归责难、公正难以及对受众隐私的侵犯问题。
1.新闻出版归责难
人工智能新闻出版常借助各类写稿机器人,即经由计算机自动生成文本系统完成新闻业务。而写稿机器人的提法其实是一种拟人化的比喻修辞术,该修辞逻辑正指向了人工智能新闻生产引发的规制难题:谁是新闻生产主体?谁该为新闻内容负责?如果说以往人们借助计算机技术实现的信息搜集和编排算不上真正的智能出版的话,那么当下智能写稿程序的“自动成篇”甚至“自助发布”则算是正式迈过了这一门槛。在此基础上,如果写稿机器人的写作和传播有违道德伦理抑或侵犯了相关当事人的权益,那么究竟谁会被追责?
2016年1月4日14时30分,影湃新闻客户端报道“江西九江浔阳区6.9级地震”事件,一时间大批媒体争相转载报道,后被证实是假消息,出错原因正是写稿机器人系统自主录入并错误解读了地震台网站后台信息。[7]事后澎湃新闻表示“经编辑人工核实,此消息不实,向各位用户致歉”。在这一事件中,一方面是人类编辑未能及时制止机器人的信息抓取错误行为,另一方面则是大批媒体在“强影响力媒体+机器人写作”消息推送模式面前缺少辨别能力,恶化了虚假信息的社会影响和后果。
从当下媒体的信息生产和传播实践看,至少在新闻出版层面,机器人写稿、自然人写稿以及“机器人+自然人”(也被称为“增强新闻”)三种方式均已存在。不同的情境中,如何约束和规制相关主体的责任与义务?这绝不仅仅是传统的主编责任制所能完美解决的命题。
以新闻把关人理论的相关阐述而言,在卢因、怀特、巴斯等学者的不断深入发掘下,把关人这一原本意指编辑个人对不同渠道、不同稿件进行筛选的拟人化理论,已经拓展至对信息生产之组织和社会环境的整体考量。[8]概略看来,把关人理论实际上是对信息生产与传播中两个主要“控制场域”层级的总体描摹。其中,第一层级在社会、经济、文化、体制构建的大环境层面,把关人角色的扮演力量来源多样,构成出版行为的外部生态。就这一领域而言,人工智能的潜力在于“不仅能拟人似的创作、编辑、分发内容,还能监控整个社会的信息生产、流通与消费态势,为出版产业管理、文化思潮和意识形态监控提供决策服务支持”。[9]第二层级在传统出版行为的最后一环,即编辑审核、选择并重组和付诸出版阶段,把关人则主要指编辑以及扮演并履行了编辑角色的主体。目前,人工智能在出版领域已经开始逐步扮演新闻出版把关人的角色。
值得深思的是,出版把关人的行为目的究竟为何?单以第二层级的出版把关行为而言,传统自然人编辑的把关行为主要是为了发掘高质量的、合乎刊物要求的稿件内容并予以实施,但人工智能所承担的把关人行为目的却是“被賦予”的——是人类对人工智能的应用以及具体的程序设定与编写决定了其把关行为。由此,人工智能出版的把关人角色背后实际上是人类编辑与智能程序编写者、使用者的另一层集体把关。可以说,在人工智能介入的新闻出版活动中,新闻出版行为与人工智能把关人、人类编辑与智能编写者把关人之间形成了嵌套关系(见图1)。
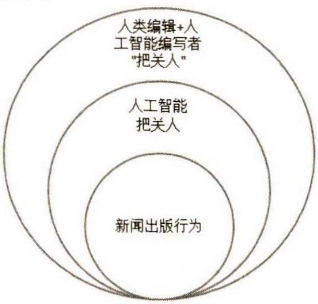
图1 人工智能新闻出版的把关人关系图
伴随着当下人工智能技术在社会生活各方面的不断渗透,人类编辑和人工智能编写者致力于将智能技术更深入地运用到出版领域,人工智能把关人自主、自助程度的加深则意味着其开始攫取更多的把关权。实际上,目前涌现的“机器将取代人类编辑”“机器人取代记者”等言论正是对此可能性所表达的担忧。
2.出版受众隐私保护难
人工智能技术离不开对海量数据的挖掘和使用,伴随着各种类型的数据采集手段的使用,智能技术逐渐掌握了人们身体生理数据、工作生活数据与个人喜好数据等。对这些数据的搜集和使用,极易侵犯个人隐私。从表面看,较多新闻出版应用在用户下载该软件或者使用某项功能时,都会提供需要用户点击“同意”或者“通过”的选项,但这往往只是被用来规避运营风险。事实上,如果用户点击“不同意”或者“拒绝通过”,绝大多数应用都不能被顺利或完整地使用。
学界对隐私权的区分大致有空间隐私、信息隐私和自决隐私三种,其中自决隐私指个人不受外界干扰、可自主决定其隐私生活的权利。[10]自决隐私权意味着个体可以决定如何使用以及在何种程度上公开自己信息,该权利容易遭遇人工智能技术的侵犯。2018年1月,今日头条被爆出“使用手机麦克风监听用户说话”,甚至不少用户表示自己遭遇过今日头条即时推送有关自己和朋友通话中所提及事件之关联新闻的情况。对此,今日头条官方头条号回应:“除非用户明确点击授权”,否则自己“无法取得权限”,同时声明旗下产品尚“达不到通过麦克风”去获取个人隐私的水平。[11]此事件中,即使悬置今日头条对用户隐私的侵犯程度不论,仍然可被洞悉的是用户事前并不完全知悉自身信息可能被获取,而应用开发和运营方也未能做到充分告知。与该事件性质相似,国外如Google等互联网巨头近年来多次被爆出侵犯用户隐私并被处以巨额罚金,网络空间内数据爬梳和抓取行为的无节制已严重侵害用户权益。
以新闻阅读和消息获取而言,在人工智能技术基础上,只要将用户的各方数据聚合分析,就能较全面地为个人画像,了解其阅读喜好和知识接受偏好,甚至预测其潜在需求并进行针对性新闻信息推送。但如果“个性化定制过程伴随着对个人隐私的发现和曝光”,[12]技术的便利并不能成就相关行为的合法性。以当下网络媒体普遍采用的、需要用户确认同意的所谓“隐私公开声明”而言,大多条目繁多混杂且不清晰,“其复杂性及其混杂的信息进一步阻碍了个人隐私保护的制定”。[13]此外,人工智能应用本身并非无懈可击,较多程序在成熟完善过程中依旧存在容易被黑客、不法分子攻击的编写漏洞,一旦用户信息泄露,其危害性难以估量。
人工智能深度洗礼人类社会的时代即将来临,大众所裹挟滋生的海量数据已成为极其重要的经济、文化甚至战略资源,所有获取相应数据的行为都应得到审视,以此确保其不会侵犯社会成员的应有权利。
3.智能系统算法“公正难”
粗略看来,基于数据和算法而实现的人工智能新闻出版应当更加客观,然而事实并非如此。智能算法会因为训练数据系统的选择、交互学习过程影响等原因产生偏见与歧视。训练数据系统选择偏见是指计算机深度学习数据集本身便是狭隘和片面的;交互学习影响偏见是指智能传播过程中所遭遇的影响滋生了偏见。就前者而言,2018年7月,美国某APP人工智能运算系统将用户上传的美国《独立宣言》认定为“含有检测种族歧视”将其删除,之后该APP将其恢复并公开道歉,指出出现误删的原因是《独立宣言》内出现了“印第安野蛮者”词汇并被算法迅速捕捉识别。尽管当年《独立宣言》起草者显然对印第安人缺乏尊重,但这也暴露了该智能算法数据集对《独立宣言》的认知缺失,同时表明其尚不具备综合考量语言使用时代背景的能力。就以后者而言,2016年3月,微软聊天机器人Tay便由于受到某个论坛用户群的密集影响,迅速学习了大量种族主义言论,从而在后续聊天中变成了一个彻底的“种族主义者”。
个性化定制新闻往往裹挟着智能系统选择偏见。以网络新闻出版为例,各类人工智能算法推荐都倾向于提供与用户个人喜好、想法高度匹配的内容。这一方面是所谓个性化定制新闻的题中之义,另一方面又是对用户偏好的刻意迎合。如果说数据算法在主动地屏蔽以及选择特定的信息推送给特定用户,那么人工智能则是在选择它认为用户愿意看到的内容。于是,特定立场的新闻信息在“迎合”和“重复”的推送过程中被逐步强化和放大,最终变成对用户已有刻板印象的再次呼应。用户被各类智能化应用建构的“过滤气泡”(filter bubble)包围,通过后者感受世界并做出决策,但又无法摆脱其带来的选择偏见,实际上被限制在“信息苗房”之中。[14]人工智能裹挟的算法偏见在相当程度上消解了个体认知世界的全面性和有效性。对用户而言,对特定微信号、头条号的关注已是媒介使用常态,然而正是这些应用平台的选择构建了让其难以突围的信息壁垒。数据偏见由此发生,所有的“其他信息”被智能算法屏蔽,而这一过程甚至难以被用户所了解。与之相伴,围绕个人的社交网络往往建立在共同的偏好与兴趣上,特定社交群体中使用的媒介工具、应用种类甚至线下活动都有高度的相似性或重叠性,这会再次固化个体的认知,让其沉浸于“世界就是如此”的舒适感中无法自拔。
詹姆斯•韦伯斯特认为,互联网和大数据实现的媒介测量本身便存在三个方面的偏见,即行为偏见、个性化偏见与流行度偏见。[15]其中,行为偏见主要指媒介测量算法存在将用户选择行为与用户偏好混为一谈的倾向;个性化偏见与流行度偏见二者均指个体的信息接受与媒介喜好受到多重影响,难以实现“自主”。这几种偏见在人工智能新闻生产中同样存在。第一,行为偏见。在广播、电视、网络媒体等媒体形态的演进历程中,将用户行为作为媒介测量的重要指标已成为一个传统。网络时代在这一向度的发展主要体现为从点击率、转发率(性质等同于收视率与收听率)等表层数据拓展到用户评论、购买、分享等多元行为统计。然而,用户行为的背后存在诸多复杂动因,用户选择行为未必一定会指向其真正的喜好。正如丹尼斯•麦奎尔在梳理受众研究时指出的那样,尽管需求模式存在规律性,但用户品位、偏好和兴趣受到文化背景与社交网络的影响,实际上较难精准解释和预测。[16]
第二,个性化偏见。人工智能新闻生产模式下,出版的审核者从传统人工编辑变成了计算机算法。算法本身更关注的是看起来似乎清晰明了的“个人喜好”,所能实现的是貌似更简单有效的“个性推荐”。这一切都建立在把握用户行为一归纳用户喜好一做出推荐行动的线性逻辑之上,却不曾诉诸更深层面,即用户喜好的成因以及该喜好是否为真?它在多大程度上受到媒介“过滤气泡”的影响?
第三,流行度偏见。大数据测量往往把媒介使用指数(如阅读量、点击率等)作为流行度参照依据,认为该类指数是大量个体独立选择和决定的结果汇总。事实却正好相反,人们的媒介使用和媒介内容接受容易追随别人的喜好而定,特别是受那些意见领袖或大众偶像的影响,因此所谓真正的“自主决策”是相对困难的。
三、人工智能新闻出版的监管优化路向
针对上述人工智能新闻出版中的监管难点,应从多方面入手,寻求应对之道。从目前可行性路向看,主要集中在以下几方面。
1.探索主体归责办法
人工智能新闻出版监管需探索出台针对性的归责办法。有学者认为厘清人工智能创作物权利主体应针对人工智能发展的不同阶段展开讨论,主张由智能软件编程者和创作作品者共享权利,指出当未来人工智能创作出“算法之外的作品”时,可考虑野其权利主体地位。[17]
从目前人工智能发展水准及新闻出版实践看,人类编辑、人工智能算法及软件编写者、使用者(含平台和个人)是主要的新闻出版主体。对特定新闻作品而言,新闻工作者所应担负的责任与义务首先应由三方共同承担,但在实际操作中则应视具体情形而定。大多数情况下,对人工智能新闻出版进行归责势必关涉法律与伦理两大领域,准确分配各方主体的法律责任份额是亟待探讨的命题。基于此,有三个方面必须兼顾。其一,归责办法必须与现有的法律规制相兼容。应更多地从新闻出版宏观规律出发,高度契合现有规制制度,探索归责办法的科学性与适应性。其二,重视政府监管与干预。归责办法需要制度化,具体责任承担和义务履行应由政府部门监督引导,同时注重干预措施的灵活性和包容性,鼓励传媒企业在新闻出版方面的探索创新。其三,动态调适与把握节点。人工智能新闻出版监管规则的制定应是一个动态完善不断调适的过程,要在综合把握各方主体并持续反馈调适效果的基础上建构治理程序。
2.建立多维互促监管模式
智能算法的作用机制往往是相对隐蔽的,需要更多“有形之手”加以引导。人工智能新闻出版主要有三极监管引导主体,分别是人类编辑、智能算法与软件编写者、智能软件使用方三者构成的自律主体;政府部门与相关组织构成的监管主体;新闻媒体与用户群体构成的监督主体。三极主体间是协调配合的互促共治关系,既层层递进,又相互监督(见图2)。
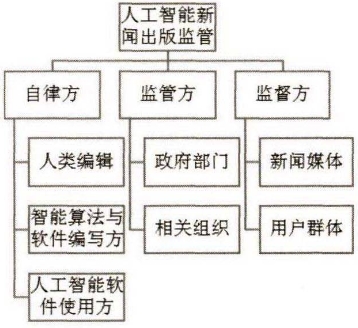
图2 人工智能新闻出版多维互促监管模式图
(1)自律主体是基础
互联网与数字技术创新基础上衍生的业态内容驳杂、数据庞大、形态多元。此种情形下,以往由监管部门全面覆盖甚至逐个检查的做法较难达到理想效果,于是便催生出政府部门将部分监督权让渡给相关企业、组织与个人的行为。具体到人工智能介入的新闻生产领域,智能程序编写者与人类编辑、智能软件使用者均负有自律责任,三者间身份可以交叉,共同构建智能化新闻生产与传播的第一道防火墙。
(2)监管主体是方向
政府部门的监管引导不可或缺,将为自律行为提供具体依据和方向导引。在此基础上,相关企业组织、行业联盟与协会则同样负有监管义务,成为由政府部门批准成立、企业与其他相关主体负责的辅助组织。
(3)监督主体是动力
新闻媒体和用户群体发挥监督职能,通过新闻报道和口碑评价、网络舆论等构成评价引导力量,成为另一极重要的监管主体。
3.为人工智能新闻出版系统“袪魅”
韦伯曾把西方社会转型的理性化过程描述为一场漫长的“祛魅”过程,其间,理性逐渐战胜非理性,现代社会逐渐消除蒙昧和神秘主义。[18]网络媒体及其不断滋养衍生的新兴技术与业态同样需要经历一个“祛魅”阶段。当下,人工智能新闻的算法和决策系统尚不为大众所了解,受众往往惊讶于智能新闻的庞杂和高效,在为其所震惊的同时也因对其不了解而徒增不信任和消极认知。未来应进一步提升人工智能算法和决策系统的透明度,用通俗易被理解的语言与形式告知大众智能决策的道理与逻辑,让大众了解所谓人工智能新闻是如何被生产和传播的、知道一个热点事件是如何被甄别选择的。同理,如果人工智能新闻系统造成了某些危害,那么其危害原因与过程也应被评定并告知大众。人们应应该能力去了解甚至介入管理对自身施加影响的智能信息生产系统,知悉并把控人工智能对自己可能施加的影响。
人工智能建立在对数据的抓取和分析基础上,由此产生类似或超出人类思考能力的效果。与此同时,大众并不了解人工智能决策的过程和机制,因而产生了接受心理的隔阂。未来监管应立足这个方面继续完善’以求达到提升大众对智能化新闻辨别与使用素养的目的。
4.降低人工智能新闻生产偏见
人工智能新闻生产之偏见产生的原因主要来自三个方面。一是由于大众被各类网络应用和移动软件包围,业已成为一个难以实现客观和独立的主体。二是因为智能新闻生产是依据一定数据集合而作,其数据选择和分析本身容易带有偏见。三是由于人工智能新闻被设定为追逐个体兴趣的“私人定制新闻”,其对个人爱好的甄别和过度推崇存在较多症结。
一定程度上,完全消除智能新闻的偏见是不可能的,因为现实中几乎不存在没有“信息噪音”的信道和天然客观的受众。然而降低智能新闻生产偏见又是极易实现的,直接有效的做法便是在一定程度上稀释个性化和定制程度,在所谓受众喜好的新闻之外提供一些“不合心意”的内容与视角,让智能定制的程度相对降低。按照美国学者凯斯•桑坦斯的说法,媒体应当向公众传递其“非计划”和“不想要”的内容,使其能够接触到更多立场和领域。[19]如此一来,被智能新闻与个性定制窄化了视野的受众方能重新打开接受场域,在“定制+非定制”的新闻信息中实现相对全面的新闻认知。智能程序的编写者应当受到约束,确保其程序算法和编写逻辑不曾逾越道德伦理的底线。智能应用的深度学习过程也应受到监督,以确保在其发生严重偏见与消极影响时能够被及时纠正。
5.建立人工智能新闻出版评测体系
应当建立人工智能新闻生产与传播的综合评测体系’探索智能化新闻内容制作与传播标准,系统化测量其伦理承载与社会影响,寻求具体的质量指标和服务标准。
人工智能新闻出版评测体系主要包括人工智能算法与程序评测、智能新闻内容评测和智能新闻效果评测。评测需依托程序编写自律方、监管方与监督方展开。其中,人工智能算法与程序评测指标包括智能转化度、伦理规范度、决策透明度;智能新闻内容评测包括影响力、覆盖力、互动力;智能新闻效果评测包括到达率、认可度、美誉度。其中,人工智能算法和程序评测用来检验和确认智能系统的可应用性和安全性,提升程序设计者的道德素养和行为规范,保证系统是安全可靠的;智能新闻内容评测用来评价新闻创作,对具体作品进行考量;智能新闻效果评测用来监督规范前两者叠加之后的具体影响,综合评价分析智能新闻业务。评测行为以政府部门支持相关协会组织实施为执行形式,引入专家、新闻工作者与受众代表等多来源评委,对特定平台在一定时间阶段内的智能化新闻行为与内容进行综合评定。上述单个指标应以综合评定为基准,着重把握人工智能新闻出版的效率和合理性,主要考量其是否在数据算法、智能应用与大众权益间构建了平衡点。
参考文献:
[1]薛亮.日本第五期科学技术基本计划推动实现超智能社会"社会5.0"[J].上海人大月刊,2017(2):53.[2]The National Artificial Intelligence Research And Development Strategic Plan[EB/0L].[2020-01-12].http://www.whitehouse.gov/ostp/nstc.
[3]腾讯研究院.人工智能各国战略解读:英国人工智能的未来监管措施与目标概述[J].电信网技术,2017(2):33-34.
[4]阿西洛马人工智能原则——马斯克、戴米斯•哈萨比斯等确认的23个原则,将使AI更安全和道德[J].智能机器人,2017(1):20-21.
[5]国务院.新一代人工智能发展规划的通知[EB/0L].[2017-07-20].http://www.gov.cn/zhengce/content/2017-07/20/content_5211996.htm.
[6]上海市人民政府办公厅.关于本市推动新一代人工智能发展的实施意见[EB/0L].[2017-11-20].http://www.sheitc.gov.cn/cyfz/675566.htm.
[7]刺猬公社."九江地震"再闹集体乌龙,哪家媒体没中招?[EB/0L].[2016-01-05],https://www.toutiao.com/16236121147469988354/.
[8]黄旦.把关人研究及其演变[J].国际新闻界,1996(41:27-31.
[9]王晓光.展望人工智能与出版的未来[J].科技与出版,2017(11):6.
[10]邵国松,黄琪.人工智能中的隐私保护问题[J].现代传播,2017(12):2.
[11]今日头条.今曰头条会窃听麦克风再给你做内容推荐?[EB/0L].[2018-02-26].http://www.sohu.com/a/214766847_115161.
[12]李修全.人工智能应用中的安全、隐私和伦理挑战及应对思考[J].科技导报,2017(15):11.
[13]孙绍谊,郑涵.新媒体与文化转型[M].上海:三联书店,2013:318.
[14]沈正赋.人工智能时代新闻业次生矛盾的生发、纠结与调适[J].编辑之友,2018(7):40.
[15]詹姆斯•韦伯斯特.注意力市场:如何吸引数字时代的受众[M].郭石晶,译•北京:中国人民大学出版社,2017:92-96.
[16]丹尼斯•麦奎尔.受众分析[M].刘燕南,等,译.北京:中国人民大学出版社,2006:100.
[17]王小夏,付强.人工智能创作物著作权问题探析[J].中国出版,2017(9):36.
[18]王泽应.祛魅的意义与危机——马克斯•韦伯祛魅观及其影响探论[J].湖南社会科学,2009(4):2.
[19]刘华栋.社交媒体"信息茧房"的隐忧与对策[J].中国广播电视学刊,2017(4):57.
