

�����������ߣ����ף��ˬB���人��ѧ���������ѧԺ
������ժ��Ҫ�ݡ�Ŀ�ġ���ѧ����������廯�����в����˴������������ݣ�������Щ�������ݵ���������Ϊ�������ʵ���ṩ�ο��ͽ������������ͨ���ռ�Ŀǰ���õĵ��Ϳ�ѧ�������������ݣ���Ƕȷ�����Щ���ݼ������͡����Ҫ�ء��������̼���֧�ֵ�Ӧ��ϵͳ���ܣ��ܽ���Щ���������ڿ��������š������еĹ��ԡ��������Ŀǰ�����Ŀ�ѧ�������������ݼ��������Ƶ����ݿ�������֯���̣�ƫ������Ȼ��ѧ�����в�ͬ����֯���ȼ�Ӧ���ص㡣�����ۡ���ѧ�������������ݵ�������Ӧ�������������ս����Ҫ�����ݵĹ淶ʹ�á����ݱ����������Լ�������Щ���ݵķ������������ӡ�
������ѧ���������������dz����ᆳ���ṹ�������廯�Ȳ������γɵ�������̬����ѧ�������������ݵ���֯�뷢��������߿�ѧ�о��ɹ��Ŀɷ����ԡ����ظ��ԣ���������ݵĻ������ԡ����о�����ѧ�������������ݼ��Ϊ����������ݣ�Semantic Publishing Data���������Ͻ���������������ǿ�ѧ���ݣ�Scientific Data����һ����̬����ͳ�Ŀ�ѧ������Ҫָ�ڿ�ѧ��������������Ŀ�ѧ�о����ݣ����ǿ��н��۵���Ҫ֤�ݼ�֧�Ų��ϣ��������ֿ�ѧʵ����۲����ݣ��Լ�����ԭʼ���ݷ������õ��Ŀ�ѧ�������ݵȡ������������������ݸ�����ǶԿ�ѧ�����ﱾ�����廯���õ������ݣ�����������˵�Ŀ��л�в��������ݡ����о���ָ����������������������׳�������廯�Ŀ�ѧ�������ݵ����͵����ݣ���Щ�������ڴ�ͳ�ڿ������顢��Ŀ�����ġ�ͼ�����Դ�Ļ����Ͼ�����Ϣ��ȡ��������֯��ת�����γɵĹ������ݣ����ߴ�һ��ʼ���ǹ������ݵ���֯��̬���ݣ�������������ǶԴ�ͳ���ֳ��������ݡ��ṹ�Ȳ��������֯���dz�������֯�뷢��������̬��Ҳ��������棨Semantic Publishing�������ݳ��棨Data Publishing��������ʵ����
��������������ʹ�ù������ݣ�Linked Data�������弼������֯����������׳������ǿ�ͳ��������̬�������ݳ�������ڴ�ͳ�����׳�����ԣ�ǿ����ѧ���ݵĿ��Ź��������ݵ��ظ����õȣ���֧�ָ��㷺�Ŀ�ѧ����������ݳ���ʵ���еĿ�ѧ���ݸ�ʽ�������ı����ݡ��������ݵ���ʽ��Ҳ�п����ǹ������ݣ������ӿ�ѧ���ݣ�Linked Scientific Data��������������ݿ��Կ����������������ݳ�����ںϣ�����������ݱ�������һ��������̬������Ϊ���ݳ���ʵ���б������Ķ���ͬʱ����������ݵ�������ʹ���˴��������弼��������������������ʵ���IJ��
������ʵ���У������������������Ŀ���ѧ���о������£�������������ݳ��潻�ڵ�����Խ��Խ���ԣ�������������漰���ݵķ��������ݳ����л�Ӧ�õ����弼�������磬�ڳ��������廯�����������Ĺ����У��Ͱ����˴�ͳ��ѧ���ݵ����廯���̣�����ͨ��������ѧ���ݱ������Կ�ѧ���ݽ�����֯���Կ�ѧ���ݽ������廯�����ȡ���������Research Object�У���������Ŀ����ѧ���ġ����л���������̡���ѧ����������Լ����л�в����Ŀ�ѧ���ݡ�����ȶ����뵽һ��ͳһ����֯��ܣ��������廯�����뷢�����Դٽ���ѧ���ݵĹ��������Լ���ѧ�ɹ����֡���Щ�о���һ���̶��Ͽɿ������������ʵ����Ҳ�ɿ��������ݳ���ʵ����
�����Ϳ�ѧ�������������ݵ���Դ���ԣ�����������ݸ����ǰ����Ŷ����������о���ʵ���������ģ�����������ҪĿ����ͨ�����ӻ�����̬�����������ע���ֶ�����ǿ����������壬���й��������������ﱳ��Ŀ�ѧ���ݣ��ḻ�������Ԫ������������Ŀɶ��ԣ������ٽ�������Ŀɷ����ԡ��ڳ�����������������ע�������Ĺ����У����ݲ�ͬ����֯���͡���֯�����Լ�ʹ�õIJ�ͬ����ģ�;ͻ�����������͵�����������ݡ���ˣ�����������ݿ�������Ҫ�ԾͲ��Զ��������о���Ҫ�۽���Ŀǰ��Ҫ������������ݼ���������Щ���ݼ������͡����Ҫ�ء����ɼ����Լ�Ӧ��״�����ܽ�Ŀǰ����������ݼ��������ص㣬���������Щ���ݼ��Ŀ��ܿ�ѧ�о���̬�����ƣ��Լ���Ϊ���ݳ����һ��������̬����ԿƼ��ڿ���չ�����塣
����1 ����������ݼ�����
�������������Ϊһ�����͵ij�������֯�����ڽ������ܵ�������ѧ�����ҵ��Ĺ㷺��ע���������ڿ��ſ�ѧ�˶��Ļ����£������ﲻ���Ǵ�ͳֽ���ڿ���������̬�����dz��ֳ����Ż�ȡ��Ԥӡ�������ݳ��桢���׳�����ͳ������Խ��Խ���š�ϸ���ȡ��ṹ�������ͳ�������̬������һ������Ҳ�������ƶ���������̬����֯�������翪��������֯��Initiative for Open Citations��I4OC���������̹�������Э��Crossref PILA��W3C��֯�µĸ��ֳ���С����Լ������������������������������ñ��壨Semantic Publishing and Referencing Ontologies��SPAR����ͬʱ����������Ӧ��Ҳ�����࣬�������ģʽҲ��һЩ�����������ɡ������������������ݳ���ʵ���Ŀ�չ���Ѿ��д���������������ݼ���������������������1������ĿǰΪֹһЩ���͵�����������ݼ���
��1 ����������ݼ�����
| ���ݼ����� | ���� | ������������Ա | ���ݼ���� |
| LOD DBLP | ������������� | Ŀǰ���ϰ��նٴ�ѧά�� | 2010�괴��,��LOD�бȽϵ��͵ij�����������ݼ�。���Ǽ�����������Ŀ���ݼ� |
| OpenCitations | �������������� | ţ���ѧ、�������Ǵ�ѧ | 2010���״η���,���������Դ��PubMed���Ż�ȡ��������。��2017��I4OC���������˶���,�����֯��ʼ����ȫ�����������ĵ���������。��http://opencitations.net��վ�Ͽ��Բ��ĸ����ݼ����µĸ���״̬。��ѭCC0Э�� |
| Semantic Lancet | �������������� | ��˼Ψ�����漯�� | 2014����,��Ϊ��˼Ψ�����漯�ŵ����������Ŀ�����������ݼ�,�����ݼ�ʹ��SPAR、CiTO�����Journal of Web Semantics���������ݽ������������,���ṩ��SPARQL、REST�ȷ�ʽ�����ݷ����ֶ�。��ѭCCBY-NC4.0Э�� |
| CEUR-WS | �������Ĺ������� | CEUR-WS.org | ĿǰCEUR-WS.org��Ҫ�����������������ֻ����ļ��Ľṹ����Ϣ |
| WikiCite | Wikidata�������� | Wikimedia����� | WikiCite��2011�걻����。Wikidata��һ���ṹ����֪ʶ��,�����˴�����������Ŀ,��Щ��Ŀ֮���зḻ�����ù�ϵ,WikiCite��������һ��������Ŀ֮������ù�ϵ�����ݼ� |
| SciGraph | ��������صĹ������� | Springer-Nature | SciGraph��Springer-Nature����2017�귢��������������ݼ�,�����˿�ѧ����、������Ŀ、����、���������Լ����������Ϣ。��SciGraph����,Springer LOD Conferenceרע�ڻ���,���������Ԫ������Ϣ,���������д、�ٿ����к�ʱ���,Ŀǰ�ṩ�˶���Щ��Ϣ�ļ����ӿ�。��ѭCC BY-NC4.0Э�� |
| OpenAIRE | �������Լ����ӿ�ѧ���� | ŷ��ίԱ�� | 2009��������һ����Ŀ,��侭����OpenAIREPLUS��Ŀ。Ŀǰ����Ŀ��OpenAIRE2020,ʼ��2015��,�����������Լ����ֿ�ѧ���ݼ� |
| Nanopublication | ���׳����� | TobiasKuhnandJuanBanda | ��ѭ���׳�����ԭ��,Ŀǰ�����׳�������Ҫ��Դ������ҽѧ�������,����ҩ�サ������(Drug-Drug Interactions)、��������(neXtProt Protein Data)、������������(WikiPathways)�� |
| SciKG | ѧ���罻���� | �廪��ѧ | 2017�귢��,SciKGĿǰ�����������ѧ�������Ҫ����、ר�Һ����ĵ�֪ʶͼ������ |
| AceKG | ������������� | �Ϻ���ͨ��ѧ | 2018�귢��,AceKG�����˴����������、����、�ڿ�、����、����、������λ���������� |
����Ŀǰ������������ݵ������Դ�ǹ����������ݣ�Linked Open Data��LOD�������������е����ݼ������°��LOD���ݣ�2018-04-30�棩�е�����������ݼ�����156����Լռ����LOD���ݼ���13.2%��156/1184����ͨ������LOD�е���Щ����������ݷ��֣���Щ������Ҫ����ͼ�����Ŀ���ݡ����Ż�ȡ�ڿ����ݡ��Ļ��Ų����ݡ���ѧ�γ���Դ��ѧλ�������ݡ�ѧ��������Ϣ�������������ݡ���ʷ�������ݡ�����ʱ���������ѧ���Ķ��б����ݵȡ�LOD���������ݵķ�����Ҫ����������ǣ������ݼ������LOD�����е����ݽ��й��������߱������ӡ���1�е�LOD DBLP����һ���Ƚ��д����Ե����ݼ�����DBLP���Ƶ����ݻ������������Э�ᣨAssociation for Computing Machinery��ACM���������͵��ӹ���ʦЭ�ᣨInstitute of Electrical and Electronics Engineers��IEEE���ȹ������ݡ���1�г���DBLP��Nanopublication�⣬�������ݲ�û����LOD�����ӻ�ע�ᡣ
����2 ����������ݼ��ṹҪ��
������LOD������������У�DBLP������͵��������ݼ�֮һ�������ӵ��������ݼ�������Ϊ34�������������ݼ����ӵ���ĿΪ31��������������������ݼ��й�������ߵ�һ����Ŀǰ�����ݼ��к���24112294����Ԫ�顣���DBLP��������XML��ʽ�ģ���˶������ָ�ʽ�������ݼ�����ת��Ϊ��Դ������ܣ�Resource Description Framework��RDF���������ݡ�OpenCitations���ݼ���ѭFAIRԭ����RDF��ʽ��ʹ��SPAR�����OpenCitations��������֯���ݡ�Ŀǰ���������˶��Լ�OpenCitations���ݵķ��������Ӵ����Ѿ�������������̵�֧�֡�WikiCite����Wikidata��Դ�������䴴�����õĻ��������˺ܶ�Wikidata���е�����ģ�ͣ���˸��������ݿ�����Wikidata�ĸ���ҳ�����Ŀ֮�������Ч���ӣ�ͬʱ������ģ��Ҳ���Ա��������ݼ���ʹ�á�Springer-Nature��SciGraphĿǰ����1.55�ڸ���Ԫ�飬�������ڳ������������µ����ݡ�Ŀǰ�����ݼ�������2012—2016���Springer-Nature�ڿ����ݡ�OpenAIRE���Կ���һ�����ŵļ������ӿ�ѧ���ݵ�ƽ̨����Կ�ѧ���ݺ��ֻ���������Ŀ���й�����������Ҫ�����ڸ������ݵ��ṩ�ߣ�����ѭOpenAIRE�����ݻ�ȡ���ߣ�Ŀǰ��Ҫ����ŷ�ޣ���δ������չ��ȫ��ļƻ�������2018��3�£�OpenAIRE���Ѿ���1153�������ṩ�ߡ�Ŀǰ�����ݸ�ʽ��ѭOpenAire Format��OAF���������ṩ�߿���ͨ��OpenAIRE����֤���߶����ύ�����ݼ����м�������֤��SciKG���ݼ���һ��ѧ���罻���ݼ���ѧ����������AMiner���ǻ��ڸ����ݼ������ġ���SciKG���ƣ�AceKG��һ��ѧ���������ݼ�������ѧ��������㣬�������罻���ԡ�
������2��������Щ����������ݼ����ݵ���Ҫ����Ҫ�أ��Լ����ݼ�ʹ���ⲿ�ʻ�����ݵ������ͨ���������Է��֣�Ŀǰ����������ݵ�ѧ����Դ�Լ����������ҽѧ���ٿƵ��������Ӷ࣬��ȫ��������ݼ�Ҳ�У����Ϻ���ͨ��ѧ��AceKG���ݼ�������֯�����ϣ���Щ���ݼ������������дֶ��Ḵ�����еı����ܻ�����ʻ㣬����������������Դ���й���������ͳ���������ص�SPAR���塢�����ֺ��Ĵʻ㡢��֪ʶ��֯ϵͳ��Simple Knowledge Organization System��SKOS���ȣ��Լ�����������ɫ��������Դ������壨Gene Ontology��GO����ҽѧ����ʱ���Medical Subject Headings��MeSH����ACM�������ϵͳ�ȣ�������������ݷ����IJο�ԭ�����⣬����Щ����������ݵ���������Ͽ�����ҪΧ�Ƴ������Ԫ������Ϣ��������֮��IJο�������Ϣ����������ص�ʵ��Ԫ������Ϣ����༭�����ߡ����������顢�ڿ��������̵ȣ��Լ���Щʵ��֮��Ĺ�ϵ����֯����֯�����ȴֻ����ڳ������Ԫ���ݲ��棬���뵽���������ݲ������֯��̬Ŀǰֻ��Nanopublication��һ�����ݼ���
��2 ����������ݼ��ṹҪ��
| ���ݼ����� | ������ɽṹ | ʹ�����еĴʻ�、����,���ӵ��ⲿ�����ݼ� |
| LOD DBLP | �����������ڿ�����、ͼ��、ѧλ����、��ѧ����、�༭��Ա、����ʽ������、��������ֻ����ĵ�Ԫ������Ϣ | Dublin Core、Foaf、AKT�ο����� |
| OpenCitations | ��������、ͼ���½�、�ڿ����ĵ�֮���������Ϣ,�Լ��������、ͼ��、�ڿ�、������、�༭�ȼ��ϵ�Ԫ������Ϣ | SPAR����、OpenCitations����、Data Catalog、VoID、PROV����ģ�� |
| SemanticLancet | JournalofWebSemantics������Ԫ������Ϣ,�Լ��ÿ�����֮����������� | FABIO����、C4O����、PROV����ģ��、WordNet、DBpedia |
| CEUR-WS | �������������ֻ�Ԫ������Ϣ,�������ֻ�����、�ٰ�ʱ��、�ص�、���ļ�������、���߷��ʵ�ַ�� | �� |
| WikiCite | ά����Ŀ�аٿƴ���、��ҳ、��Ʒ、�����ڿ����µ�֮���������Ϣ | Wikidata����ģ�� |
| SciGraph | ��Ҫ������ѧ����、�ڿ�、ѧ�����������Լ����ĵ�Ԫ������Ϣ,�Լ���ЩҪ��֮���������Ϣ | Grid����、ANZSRC���෨、SciGraph���ı���、SKOS、DBPedia、MeSH、CRM�� |
| OpenAIRE | ��Ҫ���������ṩ���ṩ���������ݺ��ֿ�������,OpenAIRE���ύ�����ݽ���Ԫ���ݲ����Լ��,�������ݵ�ID、����、������、����、����、������、��ݵ��ֶ� | Dublin Core、DataCite XML Schema、OAI-PMHЭ�� |
| Nanopublication | ��Ҫ��������、��Դ�ͳ�������Ϣ3������,���ڱ�������ĵĿ�ѧ��ʵ�Ϳ�ѧ���� | GO、MeSH�� |
| SciKG | ��Ҫ��������������ѧ����Ϣ,��ְλ、��������、�о���Ȥ、�罻�˺�、��ϵ��ʽ��,�Լ����ĵ�Ԫ������Ϣ、�о�������Ϣ�� | ACM�������ϵͳ、ά���ٿ� |
| AceKG | �ڶ�ѧ�����������、����、�ڿ�、����、����、������λ��Ԫ������Ϣ����֮���ϵ���������� | �� |
����3 ����������ݼ���������
����LOD DBLPֱ����ԭʼ��XML��ʽ��DBLP���ݿ�ת��������CEUR-WS�������ݼ���PDF��ʽ�����ֻ��������ݽ����ı�ת���������ע���ⲿ���ӣ�����RDF�������ݵĸ�ʽ��ͬʱ����Figshare.com��վ���ҵ�������ԴԪ���ݶ�Ӧ��ʵ�塢������Ϣ������ӳ�䣻����Figshare.com��վ�ϵ������е�������Ϣ��Ҳ�ҵ�����Ӧ��DOI��Ϣ��������Nanopublication���ݼ�Ŀǰ��Ҫ�Ǵӽṹ��������ҽѧ�����г�ȡת����������WikiPathways��Biological Expression Language��BEL�����ݵȡ�Semantic Lancet���ݼ���ͨ����ȡJournal of Web Semantics���������ݣ���ʹ��SPAR�ȱ�����б������ɶ����ɵġ�Springer��SciGraph���ݼ�����ʹ����ETL��Extract Transform Load����������ȡ��Щ�������ݣ����а����˴��������ݳ�ȡ����
����OpenCitations���ݼ�����ʹ��Europe PubMed Central API��PubMed�г�ȡ���Ż�ȡ���µIJο������б�������JSON��ʽ�����ݣ�Ȼ�������Щ���ݣ�ʹ��Crossref API��ORCID API�����ռ�����Ĺ�����Щ�������ݵIJ������ݣ���ת��ΪRDF��ʽ����Ϊ�������ݡ�
����Ŀǰ��WikiCite��Ŀ���ڽ��е��У����о��ļ������������������Ŀ����Դ��Ԫ����ģ�͡�������Ϣ�ij�ȡ���ѯ����Ч�ı���������Ϊ�������ó��ֵ�λ�á����õ�Ŀ��Դ�ȣ����Զ���Wikidata������������Ϣ��Wikidata�ṹ�����ݵ������ѯ��Wikidata���ݵļ��ɵȡ���WikiCite��Ŀ�������£�Ӣ��ά���ٿƵ�PubMed Central ID��PMCID������ĿԪ�����Լ���������ҽѧ������������������Ѿ����ɽ���Wikidata��
����SciKG��������ѧ��ͼ�ף�Microsoft Academic Graph��MAG�����ݣ�����Ϊѧ����������AMiner��֧�����ݡ��������ݼ�ʹ�õ�֪ʶ��ȡ���ļ������������罻������Facebook��Twitter��ʶ��ȡѧ�����ߣ�������ͬ�罻ƽ̨��ѧ���罻������������ںϣ��漰��ʵ�����缼����Ҳ��Ҫ�ֹ��������ڰ��ķ���������������ݼ����������������ݼ������������ݡ�ѧ���罻�������ݡ���ʦ��ѧ����ϵ���ݡ�����Ĺ�ͬ�������ݡ�����������Լ��������ݡ��������������ݡ������������ݡ��������ӱ�ע���ݵȡ�AceKG��ֱ�Ӵ��Ϻ���ͨ��ѧ������ѧ����������Acemap�ĺ�̨�����о�����ȡ����ʽת����������Щ���ݼ������ɷ�ʽ����ͨ��ͼ1��ʾ��������չʾ�����ȣ��ռ����ֲ�ͬ�ṹ���̶ȵ�ѧ����Դ������ѧ����վ���ṹ�����ݡ�ѧ��������������ݿ��Ԥ��������Դ��Ȼ����������������������ݳ�ȡ��ת���Լ���ϴ��Ԥ������������ԭʼ��Դ���нṹ����֮��ͨ�����뱾�塢�ʻ㡢���ݼ����ⲿ��Դ��Ԥ����֮������ݽ������ݱ������ṹ����ʾ����֯�������е����ݼ���������ӳ�䣬����������֯�����������ʽ�������������ݷ���֮ǰ��Ϊ�˱�֤�������ݵ�������һ��Ҳ��������������������̣���������շ������ݵ���������ͨ���ڰ��ķ�ʽ�����������㷨���Դ��������⡣��������ݷ����ĽΣ�һ����ṩ����API���ݷ��ʽӿ���֧�Ż�����Щ����֮�ϵ�Ӧ�á���Ȼ��ʵ�������һ����ȫ���������������ڣ���Щ����������ݴ�������ʼ���ǽṹ���˵��������ݡ�
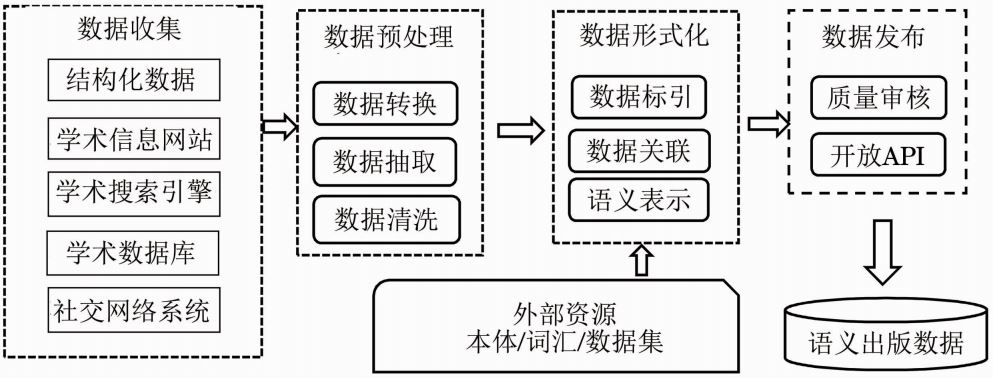
ͼ1 �����������������������
����4 ��������������ݼ���Ӧ��ϵͳ����
����DBLP��LOD���ݼ�Ҫ�����ݼ��е�ͳһ��Դ��ʶ����Uniform Resource Identifier��URI�������ǿ��Խ����ģ�ͬʱ���ݼ�������������ݼ��������ӡ���Щ���ݼ�һ�㶼���ṩSPARQL��ѯ��������������������صȷ�����ʽ���ɹ������ⲿ������á�SciGraphĿǰ�Ƽ�ʹ��Elastic���е�ElasticSearch��Kibana���߽��л��ڸ����ݵ�Ӧ�ã������ѯ���������ӻ���ͳ�Ʒ����ȹ��ܡ�
����OpenAIRE�ṩ�˷��������ݵĿ���API��Ŀǰ�ṩ��ǿ��ķ����������ܣ����簴�ջ��������ߡ����ʵ�ģʽ�����Ż�ȡ���������Ƶ�����ģʽ��������ʱ�䡢�ĵ����͡����Ե�ά��������������о����ݼ�����Ŀ���о���Ա����֯����Ϣ��ͬʱҲ�ṩ�����P�������ݼ����ύ���ܣ�����δ���ṩ���ݼ�����ϴ��ת������������ݼ��ķḻ���������ݼ���ʹ�÷�����֪ʶ����
����Ŀǰ��Semantic Lancet�ṩ�����߷���������Լ��������ߡ�ժҪ�����ױ��⡢�ص����Ϣ��������Ȳ��ҹ��ܣ���������ժҪ��Ϣ����������������WordNet�Լ�DBpedia��Դ����ӳ�䡣���ڸ����廯������ժҪ���ݣ�Semantic Lancet�ṩ����������������ܣ��Լ������������ݵ����ġ����ߵ�Ӱ�������ӻ��������ܣ����ṩ�˹��ڸ����ݼ��д��ڵĴ����������ظ������ݱ��档
����WikiCiteĿǰ�ṩ��SPARQL��ѯ�����Է����û��Զ�����SPARQL��ѯ��䣬�����������������������չʾΪ���ֿ��ӻ�����ʽ�������Ǵ�ͳ�ı������ݡ�Ŀǰ��WikiCite�ṩ������ͼ��ʱ���ߡ�����ͼ����ͼ��ɢ��ͼ������ͼ��������ͼ����������ͼ����ʽ�����Ŀ��ӻ����������
�������׳�������ʽ������������ݸ�����Ϊ��δ���ij�����̬������ֱ�ӽ�����ĵĿ�ѧ��ʵ�ͽ���ʹ�ü�С������Ԫ����������֯������������شٽ���ѧ�������ѧ���ֵĽ��̣����̲���Ҫ�Ŀ�ѧʵ��ʱ�䣬�ٽ���Ϊ�㷺�Ŀ�ѧ�������ѧ���¡�ĿǰNanopublications���ݼ��Ѿ�����֯�ɷ��������磬������ص�Nanopublication�����������Է������ݣ����������ӵ��������ϡ�
����SciKG���ݼ��Ѿ�Ӧ������AMinerѧ���������棬������������ѧ��Ϊ���ģ����Լ�����ѧ�ߵ�������ͷ�Ρ����������������������о���Ȥ�����������ġ�����ָ�����ݡ��о���Ȥ����ʱ�仯���о��Ķ�����ָ�꼰��Ծ��ָ��ȣ�ͬʱ�����Է������Ƶ����ߡ��о���������ǣ��ṩ�������ߵ����������罻����ȹ��ܡ��ڸ����ݼ������ϣ�AMiner��Ϊѧ���ṩ���Ի���ѧ�������緢����������ѧ�ߡ��������������Ƽ�Ͷ����飬�Ƽ���������˵ȷ���
����OpenCitations��Ϊ�������ݼ���Ŀǰ��������������Ҫ��Ӧ�����������ķ�����ص��������о�����ѧ�������ݷ�����Ϊ��ѧ����ѧ����Ҫ�о�����ͷ������ڴ�ͳ���о������У�ͨ��ѧ�߿�չ���ķ���ʱ����Ҫ����������ѧ���ס�������¼���ݡ�����Ԥ���������ݸ�ʽת��������������������ѡ�����������ָ�ꡢ���ӻ��������������������ܽ�����ɲ��裬������������ռ���˴ֵ�ʱ�䡣OpenCitations���ݼ��Ǹ������������Ľṹ���������ݣ�OpenCitations���ݼ��ij��ּ�׳����ػ��������Ա�Ѽ����ݵ�ѹ����ͬʱ֧�ָ�Ϊȷ�ļ������������Ҳ�ƱػἫ�������Ŀǰ�Ŀ�ѧ�����о�·����
����������������������������ݼ���Ӧ��ϵͳ���������ṩ���ŵ����ݷ��ʽӿڣ���SPARQL��REST API���Ա��ڸ����Ӧ���ܹ�����ʹ����Щ���ݡ�ͬʱ����Ͽ��ӻ��������ھ�����ͳ�Ʒ����ȼ���Ϊѧ�����ṩ���ܵ�ѧ��֪ʶ������������Щϵͳ��Ŀ�꣬����������ݵ������뷢������������ѧ�������ı���Ժ�Ч�ʡ�
��������
�������о�ͨ��ϵͳ����Ŀǰ����������������ݼ���������������Щ���ݼ���ҪΧ�Ƴ������������ⲿ��Ϣ��������֯��ͨ����ο��ⲿ����ȴʻ����ݣ��������е����ݼ����й��������ݼ��������������̻�����ѭ�����ռ���Ԥ��������ʽ���������Ȼ��ڣ��������ṩ����API���ڲ��췽�棬���ȣ�����������ݵ���֯���Ȳ�ͬ���е��������������ݣ��е����ۺ��Ե�������Ŀ���ݣ��е����ݲ��漰�������ݹ������е����������뵽��ѧ���۵ȣ���Σ���Ŀǰ����������������ݶ��ԣ���Ȼ��ѧ��������ݼ�ռ�ܴ�һ���֣�����ѧ�����Ŀ�ѧ�����������������ݻ����٣�����ṩ����API�������ѯ�����ѳɹ�ʶ�����������ݼ�֮�ϵ�Ӧ�õ�ѧ�Ʒ�������ڲ�ͬ���еIJ����ڳ���������뵼������Щ���ṩ�˸�Ϊ��ȵ������ھ��֪ʶ�����ܡ�
�������Ŀǰ�������������֯���ȵIJ��죬���ڳ�����Ԫ���ݡ��������ݡ��������������ε�����������ݲ�һ������Щ���뵽���������ݽṹ����֤��ϵ���ʻ�����Ȳ�ε������������Ҫ��෴���Գ��������ݽ��нṹ�������廯����һ��ʼ���Ѿ���������ĺô������⣬��Ŀǰ����������ݼ���ѧ�Ʒֲ���������ԣ��������Ӧ����δ���������ƣ�����Ŀǰ�����ݱ��չ�����������о����������Ŀ�ѧ���������Խ��Խ��Ľṹ�����ݣ������ݵIJ�����������Ȼ��ѧ���������еģ����δ������������ݵ�������Դ�����ḻ��������������Ӧ�õ������Զ����Ǹ������ݵļ��ɻ����̬�Լ��Լ�������Ŀ��ӻ��������������ݼ�����������һ�п��Ա����ӵ���Դ�������Ը���Ӧ����̬�ṩ֧�š����磬������������ݽ��п��ӻ������ֿ��ӵij�������Ϣ�����ݣ��Է�����ͼ���ע���ݲ����ֱ�ע���ݣ��Ե�����Ϣ���ݳ��ֳ���ͼ��Ϣ�ȡ�
�����������������ݳ���ʵ���£�ת�䴫ͳѧ���ڿ��ij���˼·�������༭����ں�����������������һ���������ս������ȫ������ֳ����������켰ת���Ѷȼ���ѧ���ڿ�����������Ϊ���ڿ��ſ�ѧ�Ļ����£����ݵļӹ��������������Ѿ�Խ��Խ�ռ����ڳ�����������У��Գ�������нṹ�������廯������������ص�ʵ����Դ�����Ա����ķ�ʽ���г�����Ϳ�ѧ���ݵ����巢����������ʱ���༭�������̵���������ȡ�ľٴ롣���磬2017�귢����OpenCitation�������ݼ��������Ͳ����ںܸߵļ����ż���Ҫ���������������ݿ������ĵIJο�������Ϣ���廯�����ų������ɣ����˾ٶ�ѧ������������ش�
�����ͱ��о����������ݶ��ԣ�δ������������ݵ�������������Ҫ��ע���¼�����������⣺��1�����ݵĹ淶ʹ�ã�����ڿ�ѧ�о�����ȷ�淶��������Щ�������ݣ���θ���ʹ��Э�飬�����ݽ��ж��μӹ����ģ����ǿ�ѧ������Ľ���ǰ���2�����ݵĹ淶��֯��������֤��������������ݵ����������б�֤���ݵ�����������ø�������ڷ�������ʱ��ѭ��ص����ݱ���淶��ԭ�������������������ݣ����ǿ�ѧ�������ֵı�֤����3�������ں���Ӧ�ã�����ø�������ݷ�������������ڼ���ӿ�ֵĴ�������������������ֿ�ѧ���ۡ��ṩ֪ʶ���ַ����Լ��ṩ�µĿ�ѧ�о�ģʽ����������������ݴ�����������ȫ������Ҫ��ע���ص㡣
