

摘 要 【目的】抵制学术不端,期刊编辑责无旁贷,为促进学术生态环境净化,提出基于互联网的深度挖掘隐性学术不端的编辑策略。【方法】论述网络时代学术不端行为特征和发展趋势,以中国知网AMLC5.0为例,在总结学术不端检测系统不足的基础上,提出有针对性的解决方案。【结果】结合网络时代学术不端行为的演变,提出以AMLC为主,辅助多种检测手段,对存疑论文进行基于网络和论文本身信息的学术不端深度挖掘;根据期刊编辑出版特点增加检测次数;构建“以人为本”“人机合一”的学术不端鉴别体系。【结论】可在学术不端末端出口处筑起一道拦截网,对期刊抵制学术不端具有一定作用。
关键词 网络;学术不端;文字复制比;AMLC
1、引言
网络是当今最主要的信息传播途径之一,以“无处不在,无时不有,光速传播”为标志,近乎于零费用的信息发布,对信息传播带来翻天覆地的变化,造就了信息多源化。随着媒体融合产业的发展,媒体传播终端的多元化使信息获取更为方便,对原创作品“剪切”“复制”“粘贴”更为便捷,学术不端问题已成为期刊出版业突出的问题。有人说:“网络时代就是大量复制和拼贴”。当抄袭成为创作的思维定式,当急功近利、投机取巧渐成时尚,当“天下文章一大抄”“白抄谁不抄”,在潜移默化中成为习惯和潜意识,抄袭如今就成了公开的秘密。编辑作为守护学术净土的前沿哨兵,自然守土有责,并且责无旁贷。国内编辑学者认为,学术不端检测系统的出现极大地简化了编辑初审时对学术不端的筛查工作,将编辑从浩若烟海的信息搜寻与价值判断中解放出来。初级学术不端行为得到了根本遏制,却促使学术不端行为产生变异和升级。由于学术不端检测软件自身的局限性,单纯依靠软件已无法胜任学术不端的筛查。本文在全面分析评价学术不端检测系统的基础上,结合网络时代学术不端行为的演化,提出以AMLC5.0为主要检测软件,理性认知检测结果,辅助多种甄别手段,对存疑论文进行基于网络和论文本身信息的学术不端深度挖掘;根据期刊编辑出版特点增加检测次数;构建“以人为本”“人机合一”的学术不端鉴别体系,牢固地在学术不端出口处构筑一道拦截网。
2、网络时代学术不端行为特征和发展趋势
(1)抄袭多源化
网络是现代人的一种崭新的生活方式,是资讯和信息传播的主要通道,网络的进一步发展使数据源不断扩大和延伸。网络包罗万象,无所不有;网络缩短了时空距离,使信息的获取更为方便,也为抄袭开了方便之门。同时,人类悠久的历史、璀璨的文明、开放的信息源为抄袭提供了多元的信息渠道,使抄袭具有多源化。
(2)抄袭智能化、隐蔽化
随着学术不端检测系统的广泛应用,低技术含量的简单复制式抄袭得到了有效的遏制。但道高一尺魔高一丈,在利益的驱使下,抄袭者变换了抄袭模式,并在技术上屡屡创新,发明了许多智能化的抄袭方法,使抄袭更隐秘,加大了防范学术不端的难度。目前显性抄袭日渐稀少,隐性抄袭日益泛。
(3)抄袭常态化
抄袭、剽窃行为已呈常态化,以致蔓延成一种社会现象,成为一种普遍“潜意识”,不抄袭甚至就不会写,几乎到了“何人背后无人抄,背后何人不抄人”的地步,据某媒体揭露:16个单位25人将一篇医学论文轮番抄袭了6次。更可怕的是抄袭之风已经蔓延进校园,侵蚀了莘莘学子的心灵,“苦读报国”变味“抄袭毕业”,每到毕业季,反抄袭软件沦为抄袭者的保护神,使“抄袭保护者”月入百万。
(4)抄袭普及化
“互联网+”时代,网络几乎变得无所不能,无所不包,充斥着海量的信息,使信息来源更广泛,复制粘贴更容易,致使抄袭日益泛滥。更有甚者,职业“抄手”充任枪手直接贩卖论文,目前,网络上代写代发论文的广告遍布搜索引擎和相关网站,仅淘宝网就聚集超过500个论文中介。有人做过统计,中国买卖论文仅2007年产业规模就超过5亿,2009年论文买卖销售额近10亿元,据《北京晨报》记者调查发现,花钱买论文如同进超市,卖者明目张胆,买者心安理得。
(5)抄袭高知化
抄袭多出现在从事研究、掌握知识的人士中,大多有高学历和良好的教育背景,本是民族的脊梁,承载着大众的希望,肩负科研创新的重任,理应勤奋耕耘,科研创新报国,却为名利诱惑,因贪图捷径,欲不劳而获,一念之差而致身败名毁。
学术不端是寄生在科研机体上的一个毒瘤,却有广泛的社会基础,学术不端行为具有强烈的“抗药性”和自适应性。目前反学术不端战役的一方是少数富正义感的打假人士、检测系统开发人士和一线编辑,而另一方是却是成百上千的高智商高学历的挑战者,他们刻苦钻研,极力寻找系统弱点并破解检测。可见,反学术不端是一场持久的战争,更隐秘的深度学术不端行为将是一种趋势,防范学术不端任重而道远。
(3)国内主要检测系统
目前国内开展学术不端检测的主要网站有十余个(见表1)。检测的原理大同小异,采用自适应多阶指纹分析技术(AMLFP)、SmanrtTextMiner知识挖掘技术、数据挖掘技术等。系统各具所长,如中国知网收录数据库文献类型多,数据覆盖范围广;万方在医学文献收录出色;维普收录内部刊物和地方性期刊较多,并整合部分网络资源;而POST通过混合引擎覆盖了188亿个网页以500万篇论文等。
表1 国内主要学术不端检测系统名称及网址

经过激烈的市场竞争和运作,目前中国知网学术不端检测系统AMLC5.0在科技期刊编辑部占据了广大市场(社科期刊广泛使用中国知网的AMLC5.0的同胞“姊妹”SMCL5.0)。AMLC5.0检测启动阈值小,系统灵敏度高,对比的单元字数少,精度高。
4、AMLC检测系统主要不足
4.1、自身功能的缺陷
(1)文章格式不同检测结果不一致。系统虽支持多种格式的对比,但实际检验结果差异很大,这是由于机检对字符判断不一造成的。论文排版格式差异也导致检测结果变化。很多编辑部是以方正书版10.0的格式传给中国知网,由于方正书版软件不能直接将排版结果文件转成文本文件,转成PDF文件也只能是图片式的,只能通过第三方专业软件转成可识别的PDF或caj文件,文章外观形式一样,但编码变化致使比对结果差异较大。笔者做过试验,在中国知网检索题名“学术不端”文献,按PDF和caj格式随机下载10篇文章进行检测,理论上应为100%,但没有1篇是100%,大多在80%左右,最低的仅有43%,可见存在辨识不清、比对不准确问题。
(2)无法识别图片、公式和完整识别表格。相似语境中即使叙述的数据或符号不同,也会被认为文字重复。图表、图形、公式、数据是科技论文表述核心科学内涵不可或缺的关键要素,若不能对此进行准确比对,其科学性难以服众。
4.2、检测结果的局限性
只能按文字相同或相似来检测文字复制比,无法做到语义分析,智能程度不高。仅提示涉嫌抄袭,对合理引用和抄袭不能正确区分。检测结果显示的仅是文字复制率,检测报告中的参考文献字数不是文中引用的参考文献字数,而是文后的参考文献字数。系统在“查全”“查准”和“查实”问题上表现不理想,检测结果也不具法律效应,是否抄袭系统无法给出准确判定。
4.3、检测内容的表面性
AMLC是基于外形上的检测比对,仅判断文字是否相似,主要是实词,不能深及文字下的内涵。对“原版抄袭”敏感,但对“改版抄袭”无能为力。系统仅给出重复率,依据《著作权法》作者有引用的权利,系统却未能保障,至于重复内容是否为不当引用内容,系统无法鉴别。
4.4、本身的工具性
由于系统本身的工具和技术性质使其极易走向相反方向,不同人使用会产生不同效应,工具性特点极易被利用,可以成为“正义之剑”,也可成为“邪恶帮凶”,助纣为虐,使学术不端行为变得更隐蔽、检测更难。虽然中国知网进行了严格意义上的授权控制,但使用者只要是社会意义上的人,其负面作用就会显现。
4.5、自身的依附性检测系统必须依靠数据库。数据库的完备程度,直接影响检测结果。有部分期刊并未加入CNKI网。数据的有限性影响了AMLC检测系统的准确度。另外未实现跨语言匹配,对外文文献检测存在技术障碍,而利用“翻译法”“Goodle”等二次逆向翻译规避学术不端检测,也是隐性学术不端者常用的手段。
4.6检测与刊载不匹配
文章虽见刊,但上网有滞后期,若马上抄袭刚刚刊载的纸质版文章,因电子版尚未进入数据库,此时系统检测不出。作者投稿后,逐步上网的文章与稿件个别语句的“暗合”也造成检测数据不断提升。另外,对各编辑部存在的大量待审、待刊稿件还无法实现比对,存在一稿多投的检测盲区。
5、基于网络的学术不端挖掘策略
5.1、AMLC初步筛查,基于互联网深度挖掘
处于垄断市场的目的,一些网络数据经销商鼓动期刊独家授权,致使中国知网、万方、维普数据库互不兼容。但比较而言,中国知网起步早,市场份额大,业内名声显赫,引领潮流,已成龙头老大。其学术不端检测系统面世早,功能全,数据库覆盖广,性能优,已被行业列为学术不端检测首选。正是由于数据库不全的原因,使AMLC不能代替其他检测,需要借助其他系统、手段补充查漏。因此,编辑部在进行论文相似性检测时,宜先使用AMLC进行初步筛查,根据检测结果选择进一步的处理方式。实践证明这是一种行之有效的好方法(见图1)。笔者曾遇过这种情况,有一篇来稿使用AMLC检测,文字复制比为0,通读时发现,在文档审阅栏“显示标记的原始状态”打开时,发现文章仅是修改了作者的名字和论文的格式,论文基本没做修改,而文档属性显示的文档署名和文章作者名不一致,原以为是“枪手”之作,遂增加其他补充检测手段,结果发现“维普”检测结果是和某博客重复56%,在“万方”检测和某篇会议论文重复86%,但作者不同。深入探究发现,原文是某网友博客,经人剽窃后投至会议论文,原以为会议论文对万方独家授权,为躲避筛查投到独家授权知网的编辑部,并且由原抄袭者转让给单位同事。不可否认,编辑部对来稿全部实行多网、多种手段检测有一定困难。但对于明显有疑问而AMLC系统又未检测出的稿件补充使用其他检测工具,或通过互联网进行深度挖掘是必要的。一些名家的博客、会议论文、论坛网贴,甚至期刊在自建网站上的开放存取(OA)的录用待发表的稿件,都给抄袭者以可乘之机。借助Google、GoogleScholar、NorthemLight、Yahoo、Baidu、FastScarch、众果搜网、搜狗等具有强大功能的搜索引擎深度挖掘,在存疑论文中选一组代表目的、方法、结果、结论的词作为关键词进行查询,网络检索比对,尤其关注“继承性”和“关联性”,可最大化地披露学术不端。
图1 基于互联网的学术不端深度挖掘流程
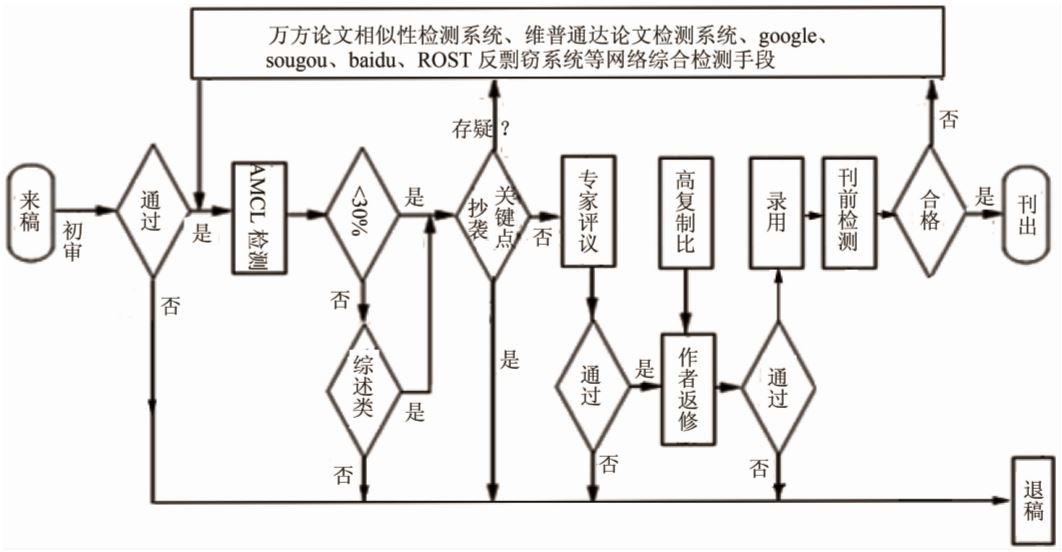
5.2、不同阶段多次检测
稿件刊发需要一定的周期,某些核心和重要期刊可能待刊更长,这期间,系统总库会有多次更新和变化,初审合格的稿件,在修回后或发表前再检测是很有必要的。检测次数2-3次为宜。但哪个阶段都不能直接将查重结果粘贴给作者,一是助长抄袭之风,二是作者藉此修改过关,但编辑时会发现很多语句根本不通,逻辑前后混乱,为稿件后期处理留下麻烦。
6、基于文章自身信息的学术不端挖掘策略
6.1、除去障眼法,看穿、伪装术
AMLC检测系统遏制了明目张胆的低层次抄袭行为,但根据进化、生态和行为原理,生物生长遇到障碍时,会产生适应性进化。为了应对系统的检测,作者能动性地升级了造假版本。抄袭者将原文章中的语言重新组织,或用在线软件将语句进行二次逆向翻译,词句变了,语义没变。这是躲避AMLC检测惯用手段。从语言上看:语言拗口,表述不通顺,系统虽难检出,但审稿时可发现全文整体语言风格不一致,就像平坦的公路上接了一段坎坷泥泞路。从检测结果上看:文章检测结果是“0”,并不正常,凡从事有价值的科学研究总要借鉴他人的经验和成果。牛顿说,“如果我看得更远一点的话,是因为我站在巨人的肩膀上”。目前期刊论文篇均参考文献数量已超过15篇。显然,此类论文存在刻意规避的嫌疑。从参考文献著录格式中可初觅端倪:如文后参考文献里数字间多余的空格,中英文标点混杂、全角半角格式不统一,以及文献著录格式的差异。这些透露出作者在抄袭原文后,将参考文献直接拷贝过来的信息。若参考文献无中文,则文章直接译自外文的可能性增加。
6.2、辨析痕迹,发现端倪
来稿中若出现文档非正常编辑符号,如句号是“,”,引号“”,逗号、分号、冒号使用的是英文半角;表格是图片格式;图是带杂色的扫描图,电脑系统界面不是彩色截屏;文字置入表格,表格边框被隐藏,并刻意转换为PDF文件等,可初步判定文章有复制其他文献的嫌疑。若正文字体、字号和字间距格式不统一,可能是多源拼凑而来;若文中出现“手动换行符”(软回车——暗灰色的向下小箭头,在“显示/隐藏编辑标记”,打开时就可以清楚看到);文字被框在无意义的文本框中,文字上存在“超链接”(字词带下划线,并呈淡蓝色,鼠标移至有提示),这些可初步判断来自网页复制。
6.4、借助作者信息判断
若作者电话号码属地与作者单位属地不一致,作者研究方向和作者工作单位不一致,投稿邮箱多次投寄不同作者的稿件,则可能是论文代写代发,这些论文有一个共同点,就是没有实验依据,数据全是杜撰的。
6.4、发挥人的主导作用,人机结合综合判断
AMLC是基于计算机语言的识别程序,不具备人脑对文字表达的文化内涵的理解能力。AMLC给出的标准和结论只为编辑提供度量学术不端的参考,不具法律效应,也不能直接判断文章是否抄袭,这在AMLC使用中已有说明。虽然是直接抄袭的克星,但乌龙和误伤时有发生,还要靠人力甄别。这犹如医院的病理化验报告,最终的诊断结果还是要靠人给出结论。编辑要从学术的角度审视全文,根据文字复制的内容、数量、目的等进行判断,必要的话请同行专家进一步“会诊”,审稿专家是论文价值最重要的评定者,从学术前沿创新的角度进行判断,是遏制学术不端行为的最高层级。无论以何种伪装出现的学术不端行为,终难逃“行家”的法眼。但若编辑将所有对来稿的学术价值和学术不端的判定,都推给审稿专家,显然是不行的。
7、结语
网络时代是知识和信息飞速传播的时代,为人们获取信息提供了极大的便利,也给学术不端者带来可乘之机,传统的单一的防治方法已不能见效,只能基于网络构建一主多辅、阶段性复测,可疑文献基于互联网和文献自身信息深度挖掘才能最大限度地披露学术不端。在检测过程中不能仅依靠机械检测结果作为唯一判定依据,应以人工研判为主,理性认知“文字复制比”。必须看到,以“一夫”敌“万夫”,终有倦怠失察之虞。特别是外文小语种的抄袭,AMLC检测不出,接触的人又少,只有业内专家偶然能发现,给学术不端防范带来一定的难度。再好的藩篱也难敌觊觎之心,治理学术不端终要从源头着手,改革既有功利性泛在化的科研评价机制,建立全社会诚信监督体系和学术不端预防教育和事后惩戒机制。
